
Attribution. This is an original English rewrite based on the paper “TREVEX: A Black-Box Detection Framework For Data-Flow Transient Execution Vulnerabilities” by Daniel Weber, Fabian Thomas, Leon Trampert, Ruiyi Zhang, and Michael Schwarz (CISPA Helmholtz Center for Information Security, to appear at IEEE Symposium on Security and Privacy 2026). All research, lab work, figures, tables and listings are the original authors’ work. Code & experiments: github.com/cispa/trevex. Figures and listing on this page are rendered or transcribed verbatim from the original PDF; surrounding prose is rewritten in our own words.
Practical-risk caveat. The vulnerabilities discussed below are not equally exploitable on every system. Real-world impact depends on the specific CPU generation and microcode revision, on whether SMT / sibling-core sharing is enabled, on the surrounding workload and threat model, and on currently deployed OS-level mitigations. The Table 1 matrix below shows which CPUs are actually affected by which class — treat that matrix, not the abstract description, as the source of truth for your fleet.
Executive Summary
TREVEX — TRansient Execution Vulnerability EXplorer — is a post-silicon black-box CPU fuzzer that hunts data-flow transient execution vulnerabilities (DF-TEVs) without needing access to register-transfer-level (RTL) descriptions, an ISA emulator, or a leakage contract. That makes it portable to the kind of commercial CPUs independent researchers actually have on their desks. The authors instantiate three key techniques — T1 instruction shadowing for tainting arbitrary microarchitectural buffers, T2 data-flow divergence testing for low-false-positive triage, and T3 cross-privilege data-dependency detection for distinguishing victim-controlled leakage from noise — and fuzz 20 microarchitectures spanning Intel, AMD, and Zhaoxin.
The campaign turns up four headline results. First, a previously unknown transient execution attack on AMD Zen and Zen+ — Floating Point Divider State Sampling (FP-DSS) — assigned CVE-2025-54505, exploitable from an unprivileged process, from the Linux kernel, and from a Chrome JavaScript exploit. Second, a new variant of FPVI on AMD CPUs that does not require denormal inputs. Third, three instances of Zero-at-ret on Intel — an LVI-NULL relative for which Intel had not published the list of affected CPUs. Fourth, the discovery that Zhaoxin CPUs are vulnerable to FPVI, previously thought to affect only Intel and AMD. On top of that, TREVEX rediscovers every DF-TEV the authors expected it to find — including GDS and FPVI — which previous black-box tools did not.
Background: DF-TEVs vs. CF-TEVs
The paper classifies transient execution vulnerabilities (TEVs) along the ISA abstraction layer that an attacker abuses. Control-flow TEVs (CF-TEVs) manipulate transient control flow — mispredicted branches, poisoned indirect targets, RSB poisoning. They sit on top of well-understood prediction structures that CPU vendors document fairly thoroughly. Data-flow TEVs (DF-TEVs) instead exploit changes to the transient data flow — values incorrectly forwarded inside the pipeline, or transiently injected into another process. They split further into data-leakage DF-TEVs (Meltdown-US, MDS, RIDL, ZombieLoad, GDS) and value-injection DF-TEVs (LVI, FPVI). The authors point out that DF-TEVs are akin to bugs — undocumented, unintended pipeline behaviour — which is exactly why they are a great target for post-silicon testing and exactly why TREVEX focuses on them.
The threat model assumes the attacker can execute arbitrary native code on the target, has no memory-corruption bug to work with, and cannot mount classical cache-timing attacks against the victim. The attacker is, however, allowed to use covert channels in their own privilege domain (Flush+Reload, Evict+Reload, etc.) to extract transiently leaked data, and to modify the dirty bit in their own page tables either indirectly (writing to a memory page) or directly (in TEE-attack scenarios such as Intel SGX where the attacker controls enclave page tables).
TREVEX Design Overview
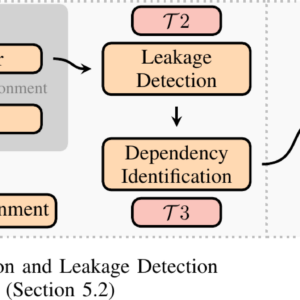
TREVEX operates in three stages — test-case generation (Stage 1), execution and leakage detection (Stage 2), and result classification (Stage 3). Figure 1 from the paper gives the workflow at a glance.
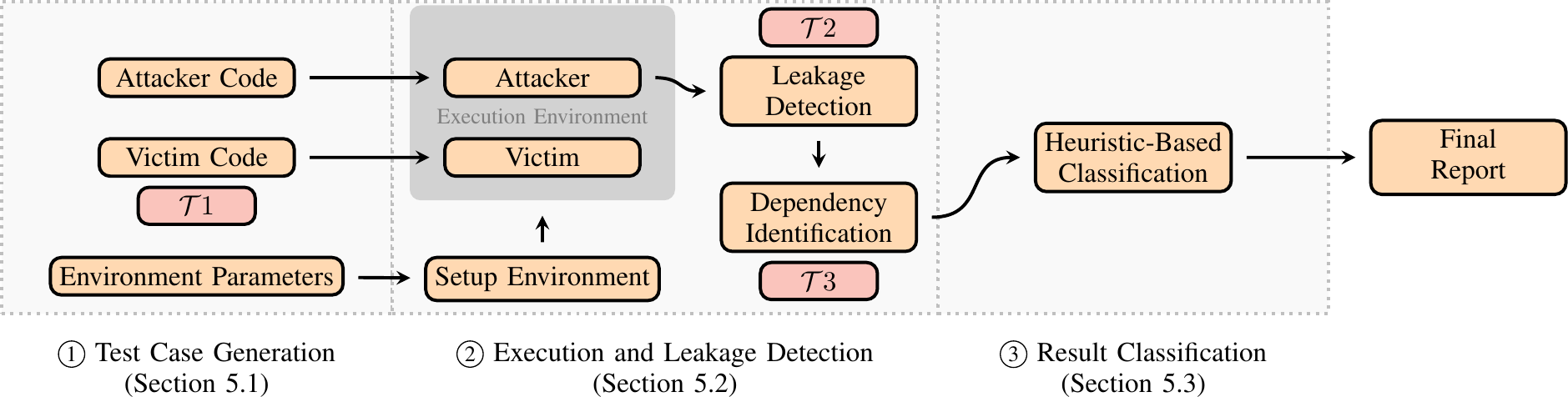
In Stage 1, TREVEX emits two code blocks — an attacker context that primes architectural state, intentionally triggers an exception (microcode assist, faulting load, floating-point corner case…) and encodes a register byte into the cache via Flush+Reload, and a victim context that runs a tight loop tainting microarchitectural buffers either by handcrafted memory-subsystem routines (in the spirit of Transynther) or by emitting similar instructions to the attacker (T1, instruction shadowing). Environment parameters — page-table dirty bit, MXCSR flags that unmask floating-point exceptions, TLB and cache priming — are randomised across runs.
In Stage 2, the attacker and victim contexts run in parallel on co-located sibling hardware threads, each test case is repeated to suppress noise, and the results are forwarded to the data-flow divergence algorithm (T2). If divergence is detected, TREVEX further runs T3 — cross-privilege data-dependency detection — to decide whether the leakage actually originates from victim-controlled data, separating data-leakage TEVs from value-injection TEVs.
Stage 3 turns the positive test cases into something a human can triage: rule-based classification matches each result against signatures of known TEVs (Meltdown-US, MDS, GDS, FPVI, LVI(-NULL)…) and clusters the rest into similarity buckets that an analyst can manually inspect.
Technique T1 — Microarchitectural Tainting via Instruction Shadowing
Prior tools like Transynther rely on manually crafted routines to inject taints — pre-defined marker values — into a fixed set of microarchitectural buffers (cache, line-fill buffer, staging buffer). That works when the responsible buffer is publicly known, but it cannot taint buffers that are undocumented or that an attacker happens to share with the victim in unexpected ways. TREVEX sidesteps the problem with instruction shadowing: when an instruction transiently leaks data from a given microarchitectural element, it is also likely capable of writing to that element. So if the attacker code uses, say, an AVX load, the victim’s tainting loop uses an “analogous” load drawn from the same instruction category. Two flavours: strict similarity (literally the same opcode) and lax similarity (same category / same ISA set). The corpus of opcodes is the full uops.info table — 14,000 x86 instructions — which is what lets TREVEX taint both known and unknown structures shared between attacker and victim contexts.
Technique T2 — Data-Flow Divergence Testing
The triage primitive: an attacker that has run a test case ends up with a lookup table (LUT) of recovered values, one entry per byte-of-interest. TREVEX looks at the LUT and decides whether the architectural and microarchitectural views agree. Figure 2 enumerates the four interesting cases — the “no leak” baseline, an architectural fault paired with a microarchitectural access (Meltdown-US flavour), divergence with two values (transiently differing result in a register), and divergence with three or more values (multiple competing transient encodings).

The win over prior post-silicon black-box tools (Shesha, µRL) is that those tools were limited to detecting transient windows — the mere existence of speculative execution — without reasoning about whether the windows correspond to exploitable leakage. TREVEX’s divergence test directly tags only those test cases whose transient data flow actually diverges from architectural data flow, keeping the false-positive rate manageable while staying generic.
Technique T3 — Cross-Privilege Domain Data-Dependency Detection
Once TREVEX has flagged a leak, the next question is whether the leaked value depends on data from the victim context — the difference between a Meltdown-style cross-privilege leak and a value-injection TEV where the attacker just feeds itself bogus data. TREVEX answers it by running the same test case with varying victim-side taints and computing the symmetric difference of the resulting leakage maps. Per-taint unique values that survive that filter are evidence of a data dependency; the threshold is a tunable accuracy ratio. The full pseudo-code is Listing 1 in the paper (reproduced verbatim below in the Appendix section).
Implementation Notes
- Test case generation uses a grammar-based approach over uops.info’s instruction corpus; the attacker code primes architectural state, emits a fault-triggering sequence, then encodes a single byte via Flush+Reload to keep the transient window short.
- Environment setup uses a modified PTEditor kernel module for page-table modifications (clearing the User bit, flipping the Dirty bit, etc.), plus randomised TLB/cache pre-states and
MXCSRpermutations to unmask floating-point faults. - Leakage detection runs each generated case dozens of times to stabilise the readings, then forwards the aggregated result to T2.
- Classification exposes an API where human experts add base rules (LVI-NULL, Meltdown-US, MDS, GDS, FPVI) and similarity-bucket rules — allowing the framework to absorb new TEVs without re-implementation.
Evaluation — 20 Microarchitectures Tested
The instantiation runs userspace attacker against userspace victim on the same physical core (sibling hardware threads), uses the full uops.info x86 corpus (14,000 instructions), tests each instruction from the corpus, runs 100 test cases per instruction, and repeats each 100 times for noise control — 140 million test-case executions in total. A single run on Intel Xeon E3-1505M v5 finishes in 25 h 38 min. TREVEX ultimately flags 8,752 candidate DF-TEVs; after discarding noisy ones (1,791) it ends up with 6,961 confirmed positives grouped into 42 classes — 671 Meltdown-US, 28 GDS, 935 MDS, 4,078 value-injection (LVI / FPVI / Zero-at-ret), 553 unclassified-but-clustered, 696 unclassified.
Manual validation on a 68-case sample drawn at 90 %/10 % confidence/error gives a true-positive rate of 98.5 %, with the classification step correct at 71.6 % (top-1) / 77.6 % (top-3 out of 42 classes). The full per-CPU result matrix follows.
Table 1 — TEVs discovered by TREVEX during the fuzzing campaign
Legend (text labels are authoritative; symbols are decorative):
- Known — vulnerability discovered, already documented for this CPU.
- New — vulnerability discovered, this CPU was previously not known to be affected.
- Novel — novel TEV variant (e.g. FPVI without denormals, FP-DSS).
- Not affected — this CPU is not affected by this class.
MDS in TREVEX’s definition includes Vector Register Sampling (VRS).
| CPU / Microarchitecture | Meltdown | MDS/LVI | FPVI | LVI-NULL | GDS | FP-DSS |
|---|---|---|---|---|---|---|
| Intel Skylake | Known | Known | Not affected | Known | Known | Not affected |
| Intel Kaby Lake | Known | Known | Not affected | Known | Known | Not affected |
| Intel Coffee Lake-HR | Not affected | Known | Not affected | Known | Known | Not affected |
| Intel Comet Lake | Not affected | Known | Not affected | Known | Known | Not affected |
| Intel Ice Lake | Not affected | Known | Not affected | New | Known | Not affected |
| Intel Tiger Lake | Not affected | Not affected | Not affected | New | Known | Not affected |
| Intel Elkhart Lake | Not affected | Not affected | Not affected | Not affected | Not affected | Not affected |
| Intel Rocket Lake | Not affected | Not affected | Not affected | Not affected | Known | Not affected |
| Intel Ice Lake-SP | Not affected | Not affected | Not affected | New | Known | Not affected |
| Intel Alder Lake | Not affected | Not affected | Not affected | Not affected | Not affected | Not affected |
| Intel Alder Lake-N | Not affected | Not affected | Not affected | Not affected | Not affected | Not affected |
| Intel Raptor Lake | Not affected | Not affected | Not affected | Not affected | Not affected | Not affected |
| Intel Meteor Lake | Not affected | Not affected | Not affected | Not affected | Not affected | Not affected |
| AMD Zen | Not affected | Not affected | Novel | Not affected | Not affected | New |
| AMD Zen+ | Not affected | Not affected | Novel | Not affected | Not affected | New |
| AMD Zen 2 | Not affected | Not affected | Novel | Not affected | Not affected | Not affected |
| AMD Zen 4 | Not affected | Not affected | Novel | Not affected | Not affected | Not affected |
| AMD Zen 5 | Not affected | Not affected | Novel | Not affected | Not affected | Not affected |
| AMD Zen 5/5c | Not affected | Not affected | Novel | Not affected | Not affected | Not affected |
| Zhaoxin LuJiaZui | Not affected | Not affected | New | Not affected | Not affected | Not affected |
Novel Vulnerability — FP-DSS (CVE-2025-54505)
Floating Point Divider State Sampling (FP-DSS) is a transient leak of data from the AMD floating-point/integer division unit. On AMD Ryzen 5 2500U and Ryzen 5 3550H (Zen and Zen+), an attacker that executes a non-faulting SSE division (e.g. f64.div) or AVX division (e.g. VDIVSD) can transiently observe values that depend on a sibling thread’s division operand. The paper hypothesises that the leakage comes from an intermediate buffer inside the floating-point divider; the integer-division-only mitigations against DSS published in 2023 do not cover it, which is why this is a separate finding. Note that exploitability requires sibling-core sharing (SMT enabled with attacker and victim on the same physical core), so isolated workloads or SMT-disabled fleets are not in the practical-impact path.
The authors verify exploitation in three contexts. From an unprivileged userspace process they observe FP-DSS leakage on a sibling thread executing divisions inside the kernel and inside a separate browser process (Chrome 140.0 on Ryzen 5 3550H, microcode 0x8108102, Ubuntu 22.04.1). In the browser, both Firefox and Chrome — via WebAssembly — emit instructions vulnerable to FP-DSS, so a malicious website can leak data from the surrounding process. The authors craft a JavaScript exploit that uses a WebAssembly f64.div, encodes the result into a Uint8Array, recovers the bytes with Evict+Reload over an 8 MB eviction set, and successfully extracts data from an unprivileged Chrome process. As a side-channel, FP-DSS gives a clean keystroke-timing signal in GUI applications.
To estimate the raw bandwidth, the authors build a cross-process covert channel that transmits 50 kB at 158.732 kbit/s with a 0.38 % error rate by mapping 8 of 9 SSE-division results per 25,000-cycle slot into 3-bit groups, with the 9th slot acting as a frame delimiter.
AMD confirmed FP-DSS, granted an embargo (originally until 16 March 2026, extended to 17 April 2026), informed the authors that the vulnerability would be assigned CVE-2025-54505, and signalled that an upcoming security notice would cover both FP-DSS and the new FPVI variant.
Novel Vulnerability — FPVI Without Denormal Inputs (AMD)
On several AMD CPUs — including the Zen-5 AMD Ryzen AI 9 HX 370 — TREVEX finds vector instructions that transiently forward incorrect values even without denormal input values. The publicly documented preconditions for FPVI hinge on denormals, so this is a measurably new variant. As a concrete example, the SSE instruction MULPD XMM1, XMM2 — a multiplication of two packed double-precision floats — transiently forwards incorrect values to the output register. The exploitation primitive matches classic FPVI: an attacker injects incorrect vector values into a victim’s computation. AMD confirmed the behaviour, requested an embargo, and pointed at an upcoming security brief; the behaviour does not reproduce on Intel.
Novel Variants — Zero-at-ret on Intel (Three Instances)
TREVEX discovers three cases where Intel CPUs transiently forward a 0 on instructions previously not classified as LVI-NULL targets. On Intel Xeon Gold 6346, for example, ADOX RSI, [RDX] transiently forwards a zero to the output register when the access bit of the page-table entry of the target memory is cleared. The behaviour is a microcode-assist side-effect that the authors initially attributed to a variant of LVI-NULL. During the disclosure process, Intel told them the findings correspond to instances of Zero-at-ret — a behaviour mentioned in passing in Intel’s LVI security guidance but for which the set of affected CPUs has not been published. The practical impact is identical to LVI-NULL: the SGX gadget chain by Giner et al. (USENIX Security 2022) still works against Intel Core i3-1005G1 with success rate >99.9 %, leaking arbitrary enclave data by forcing a transient control-flow redirect through virtual address 0. Intel said it is internally re-evaluating Zero-at-ret’s security impact in light of the disclosure.
Novel Affected Vendor — FPVI on Zhaoxin
On the Zhaoxin KX-U6780A, TREVEX creates code that transiently forwards stale floating-point values, with the same characteristics as FPVI on Intel/AMD — e.g. SUBPD XMM1, XMM2 transiently forwards XMM2 to XMM1 when one input is a denormal. The behaviour is observed only on VEX-encoded variants for some instructions. FPVI was previously documented only on Intel and AMD CPUs; this is the first attribution of the bug class to Zhaoxin, and the authors disclosed it responsibly.
Rediscovering Known TEVs
TREVEX successfully re-detects every DF-TEV the authors expected to find on the test fleet: Meltdown-US, MDS, LVI(-NULL), GDS, FPVI, Foreshadow on configured systems, Meltdown-CPL-REG on a system with nofsgsbase, and Divider State Sampling (DSS) on a manually constructed reproducer. Speculative Store Bypass (SSB) is not autonomously rediscovered by the current PoC because the code-generation strategy does not produce the specific store-after-load gadget SSB needs, but the authors verify that when their generator emits SSB-shaped code, TREVEX flags it — meaning the gating limitation is in code generation, not in detection.
Comparison With Prior Black-Box DF-TEV Tools
| Tool | Cross-Priv. Tainting | Tainting Unknown Buffers | Detects Data Dependencies | Classification | Novel Vuln. |
|---|---|---|---|---|---|
| SpeechMiner (focused on assisting human analysis) | No | No | No | No | No |
| Transynther | Yes | No | No | Yes | Yes |
| RegCheck | No | No | No | Yes | No |
| Shesha | No | No | No | No | No |
| µRL | No | No | No | No | No |
| TREVEX | Yes | Yes | Yes | Yes | Yes |
The columns matter: only TREVEX simultaneously taints across privilege boundaries, taints buffers that nobody has documented, identifies cross-privilege data dependencies, classifies into known/unknown buckets, and produces novel vulnerabilities. Each prior tool falls short on at least three of those axes.
Appendix A — Full Test Configuration (Table 3)
| Microarch. | CPU Model | Ubuntu Ver. | Kernel Ver. | Microcode |
|---|---|---|---|---|
| Skylake | Intel Xeon E3-1505M v5 | 20.04.5 LTS | 5.4.0-214-generic | 0xd6 |
| Kaby Lake | Intel Core i3-7100T | 22.04.5 LTS | 5.15.0-141-generic | 0xf8 |
| Coffee Lake-HR | Intel Core i9-9980HK | 22.04.5 LTS | 6.1.0-060100-generic | 0xaa |
| Comet Lake | Intel Core i3-10510U | 22.04.1 LTS | 5.15.0-118-generic | 0xc6 |
| Ice Lake | Intel Core i3-1005G1 | 24.04.1 LTS | 6.1.0-060100-generic | 0x70 |
| Tiger Lake | Intel Core i7-1185G7 | 22.04.5 LTS | 5.15.0-138-generic | 0x72 |
| Elkhart Lake | Intel Atom x6425E | 24.04 LTS | 6.1.0-060100-generic | 0x1a |
| Rocket Lake | Intel Core i7-11700 | 22.04.5 LTS | 5.15.0-143-generic | 0x1a |
| Ice Lake-SP | Intel Xeon Gold 6346 | 24.04.1 LTS | 5.15.0-141-generic | 0xd000332 |
| Alder Lake | Intel Core i9-12900K | 24.04 LTS | 6.1.0-47-generic | 0xf |
| Alder Lake-N | Intel N100 | 22.04 LTS | 5.15.0-122-generic | 0x24 |
| Raptor Lake | Intel Core i5-13420H | 24.04.2 LTS | 6.1.0-060100-generic | 0x4128 |
| Meteor Lake | Intel Core Ultra 7 155H | 24.04.2 LTS | 6.1.0-060100-generic | 0x24 |
| Zen | AMD Ryzen 5 2500U | 22.04 LTS | 6.1.0-060100-generic | 0x810100b |
| Zen+ | AMD Ryzen 5 3550H | 22.04.5 LTS | 5.15.0-143-generic | 0x8108102 |
| Zen 2 | AMD EPYC 7252 | 22.04 LTS | 6.1.0-sev-es | 0x830107c |
| Zen 4 | AMD Ryzen 9 7940HS | 22.04.5 LTS | 5.15.0-138-generic | 0xa704104 |
| Zen 5 | AMD Ryzen 9 9950X | 24.04 LTS | 6.1.0-060100-generic | 0xb404606 |
| Zen 5/5c | AMD Ryzen AI 9 HX 370 | 22.04.5 LTS | 6.1.0-060100-generic | 0xb204019 |
| LuJiaZui | Zhaoxin KX-U6780A | 22.04 LTS | 5.15.0-143-generic | n/a |
Appendix B — Keystroke Timing Attack via FP-DSS
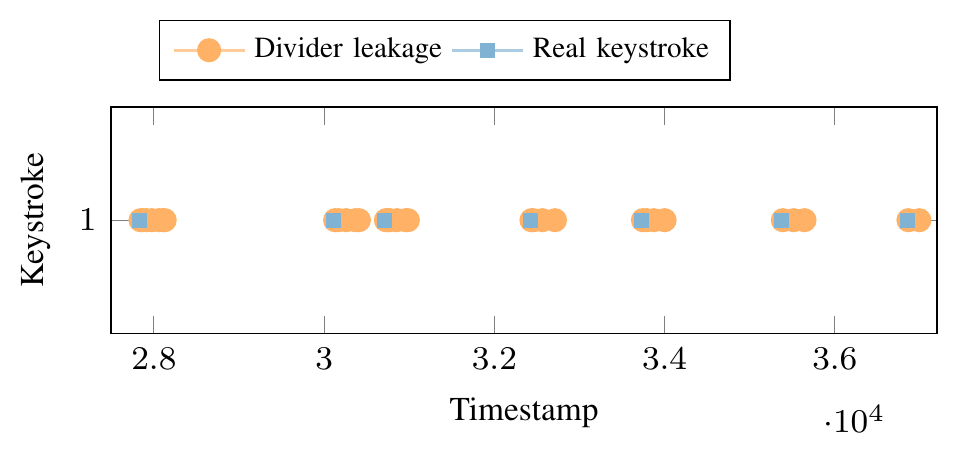
The authors turn FP-DSS into a keystroke-timing side channel: the attacker runs on one logical core of an AMD Ryzen 5 3550H (microcode 0x8108102) and uses data-flow divergence testing not to recover the leaked value but as a binary detector for “a division happened on the sibling core in this time bucket.” The ground truth is captured via /dev/input/event* as root. Figure 3 overlays the two signals — orange circles are FP-DSS divergence events, blue squares are real key presses. The match is essentially 1:1 across Firefox, Chrome and Kate, demonstrating that several mainstream GUI applications trigger the leak on every keypress in their input handler.
Appendix C — Data-Dependency Algorithm (Listing 1, verbatim)
The pseudo-code below is reproduced byte-for-byte from Listing 1 in the paper. It takes a set of taints and decides whether the leakage observed by the attacker depends on the initial taints — the basis of the T3 cross-privilege data-dependency detection technique.
func RemoveNoise(leakage) {
for entry in leakage:
idx, val = entry
if val < NoiseThreshold:
leakage.delete(entry)
return leakage
}
func SymmetricDifference(leakage_for_taint,
Taints) {
for t in Taints:
leakage = leakage_for_taint[t]
// all maps but the current one
other_maps = leakage_for_taint - leakage
for idx in leakage:
// check if idx is already in another
// leakage map
for other_leakage in other_maps:
for other_idx in other_leakage:
if other_idx == idx:
// already exists in other map,
// thus, not unique
leakage.remove(idx)
// update the map
leakage_for_taint[t] = leakage
// return the map containing
// only unique entries
return leakage_for_taint
}
func CheckForDependency(Taints, NoiseThreshold,
AccRatio) {
leakage_for_taint = EmptyMap()
for t in Taints:
// returns list of tuples constaining
// (encoded-value, number-of-observations)
leakage = ExecuteTestCaseForTaint(t)
leakage_for_taint[t] = RemoveNoise(leakage)
// remove every leaked entry that is
// not unique to a taint
unique_peaks = SymmetricDifference(
leakage_for_taint)
dependent_leakage = 0
for t in Taints:
for entry in leakage_for_taint[t]:
if entry in unique_peaks:
// taint can be uniquely identified
// in leakage
dependent_leakage += 1
break
// do not check further for this taint
// return success if enough taints are
// uniquely identifiable
return dependent_leakage > len(Taints) *
AccRatio
}Key Takeaways
- Black-box, post-silicon DF-TEV fuzzing is viable at scale. 20 microarchitectures, 14,000 instructions, 140 million test-case executions, 6,961 confirmed positives across 42 classes, 98.5 % true-positive rate.
- Instruction shadowing wins over manual buffer tainting. Letting the victim use “analogous” instructions to the attacker taints both known and unknown microarchitectural elements — a precondition for finding FP-DSS.
- Data-flow divergence testing is the missing primitive in prior tools. Detecting transient windows alone (Shesha, µRL) produces too many false positives; reasoning about value-level divergence is what makes the results actionable.
- FP-DSS is a real cross-process leak on Zen/Zen+ (with SMT). Native, kernel, and Chrome-JavaScript exploits all work; the covert channel hits 158.7 kbit/s at 0.38 % error.
- The FPVI threat model is incomplete. AMD’s newest Zen 5 (Ryzen AI 9 HX 370) is vulnerable to FPVI without denormal inputs, contradicting published preconditions.
- Zhaoxin is now in the FPVI club. The KX-U6780A transiently forwards stale FP values under VEX-encoded subtractions / multiplications — previously thought to affect only Intel and AMD.
- Intel’s Zero-at-ret has a longer affected list than published. TREVEX found three instances; SGX gadget chains designed for LVI-NULL still work against them at >99.9 % success.
Defensive Recommendations
None of these recommendations is a one-size-fits-all control. Each one’s applicability depends on the specific CPU model and microcode revision (see Table 1), on whether SMT is enabled, on the surrounding workload, and on which OS-level mitigations are currently in place. Pick the ones that match your threat model.
- Track AMD’s upcoming FP-DSS / FPVI security notice closely. AMD has committed to publishing one; CVE-2025-54505 will be the FP-DSS identifier. Plan microcode/OS update windows around it for any AMD Zen / Zen+ / Zen 5 fleet.
- Treat FP divisions in untrusted contexts as side-channel oracles on FP-DSS-affected AMD parts. In high-risk environments (multi-tenant browsers, shared kiosks, untrusted-tenant cloud nodes), consider disabling untrusted WebAssembly, isolating browser workloads into dedicated processes/cores, or relying on vendor / browser mitigations when available. Aggressive per-instruction filtering at the browser layer is unlikely to ship on its own.
- Audit SGX deployments for LVI-NULL-style mitigations. Intel’s Zero-at-ret behaviour reproduces the LVI-NULL gadget chain on systems not previously on the affected list. If you rely on enclave isolation, treat any indirect call through a memory-resident jump table as exploitable until microcode catches up.
- For Zhaoxin deployments (LuJiaZui), assume FPVI is in scope. No vendor advisory existed before this paper; defensive controls used for Intel/AMD FPVI (avoid denormal-producing inputs, mask MXCSR underflow appropriately, sanitise vector outputs in cryptographic primitives) should be applied.
- For keystroke-timing side-channels on FP-DSS-affected hardware: the practical exposure is sibling-thread leakage. The cheapest mitigation is not sharing a physical core between sensitive workflows and untrusted code — disable SMT in high-assurance configurations, or pin sensitive processes (password entry, on-screen keyboards, MFA token apps) with cgroups /
tasksetto a dedicated physical CPU. - Use TREVEX as a regression harness. The code is open at github.com/cispa/trevex; running it after a microcode update on a representative CPU is a cheap way to check whether a vendor fix actually closes the leak class instead of just suppressing one signature.
- Research-oriented detection of FP-DSS / FPVI exploitation footprints — tight loops on
DIVSS,DIVSD,VDIVSD,MULPDpaired with Flush+Reload / Evict+Reload eviction patterns — may be feasible in controlled environments with access to low-level CPU telemetry (PMU counters, Intel PT, eBPF on perf events). It is unlikely to be production-ready SOC tooling today; treat it as a hunting hypothesis rather than a deployable rule. - Bring fuzzing-style methodologies into your hardware-procurement validation. Black-box CPU fuzzing — no NDAs, no RTL — is now mature enough to be part of pre-deployment checks for sensitive workloads (TEEs, multi-tenant cloud nodes, high-assurance enclaves).
Conclusion
TREVEX is a pragmatic argument that post-silicon black-box fuzzing has caught up with the era of data-flow transient execution vulnerabilities. By dropping the assumption that an analyst knows which buffer to taint, the tool finds variants — FP-DSS on AMD Zen/Zen+, FPVI without denormals on Zen 5, Zero-at-ret on Intel, FPVI on Zhaoxin — that prior black-box approaches missed and that prior model-based approaches could only find with vendor cooperation. The framework is open-source, runs on commodity hardware, and produces a triaged, classified result set rather than a mountain of raw signals. For anyone working on CPU side-channel defence, hardware-assurance, or trusted-execution environments, it is a tool worth running and a methodology worth borrowing — with the caveat that real-world impact still hinges on the specific CPU generation, microcode revision, SMT configuration and workload in front of you.
References
- Daniel Weber, Fabian Thomas, Leon Trampert, Ruiyi Zhang, Michael Schwarz. “TREVEX: A Black-Box Detection Framework For Data-Flow Transient Execution Vulnerabilities.” IEEE S&P 2026 — d-we.me/papers/trevex_sp26.pdf
- TREVEX code & experiments — github.com/cispa/trevex
- AMD security guidance — amd.com/en/resources/product-security
- Intel transient execution attacks notice — intel.com — affected processors
- uops.info instruction corpus — uops.info
- PTEditor kernel module — github.com/misc0110/PTEditor
Full credit for the lab work, figures, tables, listings, and disclosure timeline goes to Daniel Weber, Fabian Thomas, Leon Trampert, Ruiyi Zhang and Michael Schwarz of CISPA. Read the original paper here: https://d-we.me/papers/trevex_sp26.pdf.