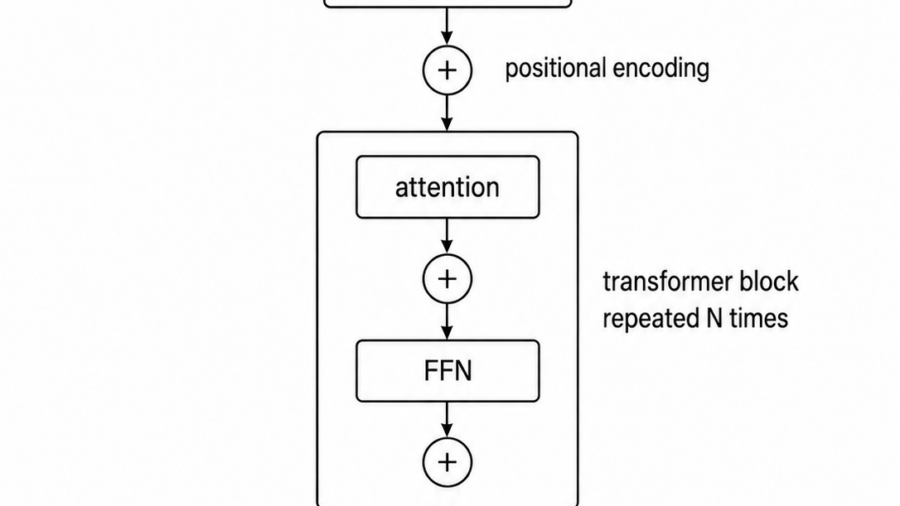
0xkato’s walkthrough of the mechanisms inside modern transformer-based LLMs — tokenization, embeddings, Rotary Position Embeddings, attention with Q/K/V and causal masking, multi-head attention and the move to Grouped-Query Attention, the feed-forward network as the stored-knowledge layer, Mixture of Experts, the residual stream + RMSNorm + pre-norm stack, and the next-token prediction loop with speculative decoding. By the end you can read a modern LLM model card and recognise which piece of the architecture each section is talking about.