

Original source: Fundamental of Virtual Memory — author not clearly listed (site: Melatoni, contact nghiant3223@gmail.com), published 2025-05-29.
This article is an original English rewrite of the topic, not a verbatim republication. Full credit for the underlying explanation, structure, and diagrams goes to the original author. Diagrams below are reproduced from the source article with attribution. Please read the original article for the author’s full treatment of the subject.
Executive Summary
Virtual memory is the abstraction that lets every process on a modern operating system pretend it has the entire address space of the machine to itself. Behind that abstraction sits a careful collaboration between the CPU’s Memory Management Unit (MMU), the operating system kernel, and on-disk storage. Understanding how it actually works is foundational to performance engineering, systems programming, exploit development, defensive security (ASLR, NX, page protections), and basically every category of low-level engineering work.
This post walks through the core mechanics: why we need virtual memory at all, what was wrong with the simple contiguous-allocation strategies that preceded it, how paging and page tables solve fragmentation, how demand paging makes lazy loading practical, how the per-process virtual address space is laid out (kernel space, stack, mmap region, heap, BSS, data, text), and how stack and heap allocation actually work in practice — including brk/sbrk, mmap, copy-on-write, and the difference between resident and virtual size.
Why Virtual Memory Exists
CPU registers are tiny and disk is enormous but slow. Main memory (RAM) sits in between and is what programs actually run against. The questions virtual memory answers are:
- How do we let multiple processes share RAM without them clobbering each other?
- How do we run programs whose total working set is larger than physical RAM?
- How do we keep address layouts predictable to programs while letting the OS move things around physically?
- How do we enforce isolation and protection (read-only code, no-execute data, kernel vs. user)?
Virtual memory answers all four by introducing an indirection: every program operates on virtual addresses, and a hardware/software combination translates those into physical addresses at access time.
Simple Allocation and Why It Failed
Before paging, operating systems used contiguous allocation: each process got one large block of RAM. The OS would find a free hole large enough and place the process there, using strategies such as:
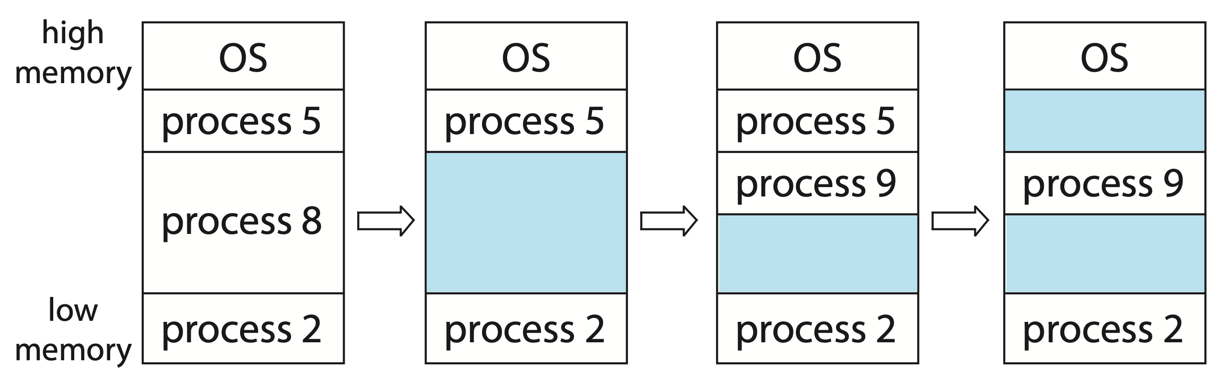
- First-fit: use the first hole that’s big enough — fast but tends to fragment the low end of memory.
- Best-fit: use the smallest hole that’s big enough — produces lots of tiny unusable leftovers.
- Worst-fit: use the largest hole — preserves usefully-sized remainders but is slow and still fragments over time.
All of them suffer from external fragmentation: even when the total free memory is large, no single contiguous hole is big enough for a new process. Compacting memory at runtime is expensive and stops the world.
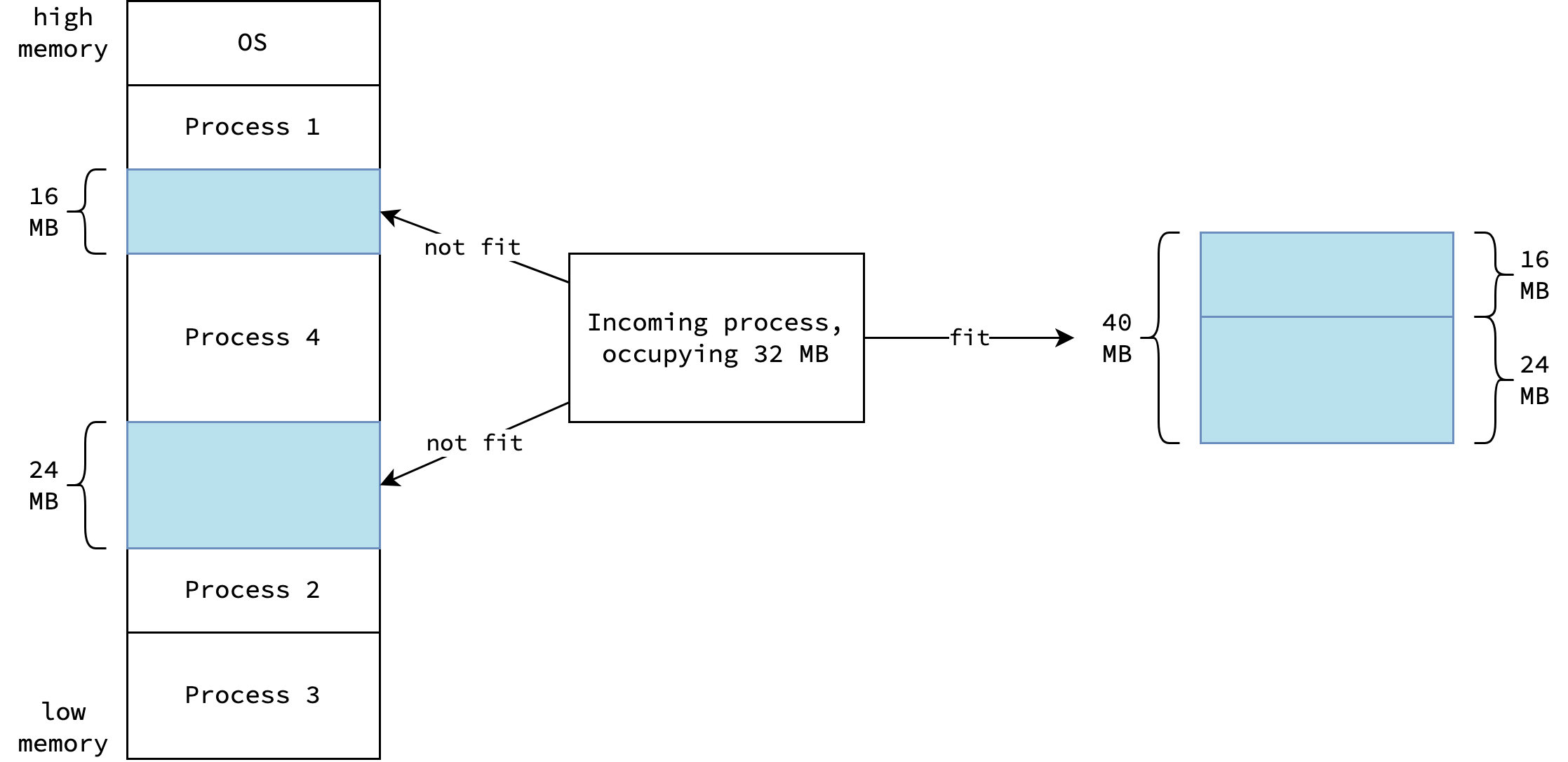
Paging solves this by abandoning the requirement that a process’s memory be physically contiguous.
Paging: The Foundational Trick
Physical RAM is divided into fixed-size frames (typically 4 KiB on x86-64, with optional 2 MiB and 1 GiB huge pages). Each process’s virtual address space is divided into equally-sized pages. The OS, with help from the MMU, maintains a page table mapping each virtual page to a physical frame.
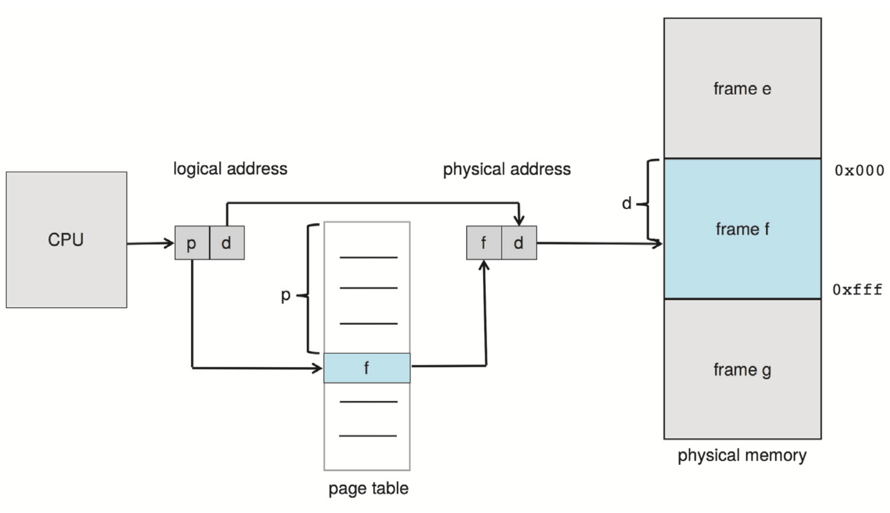
A virtual address is split into a page number and an offset within the page. The MMU uses the page number to index the page table, retrieves the frame number, and concatenates it with the offset to get the physical address. The Translation Lookaside Buffer (TLB) caches recent translations to make this fast.
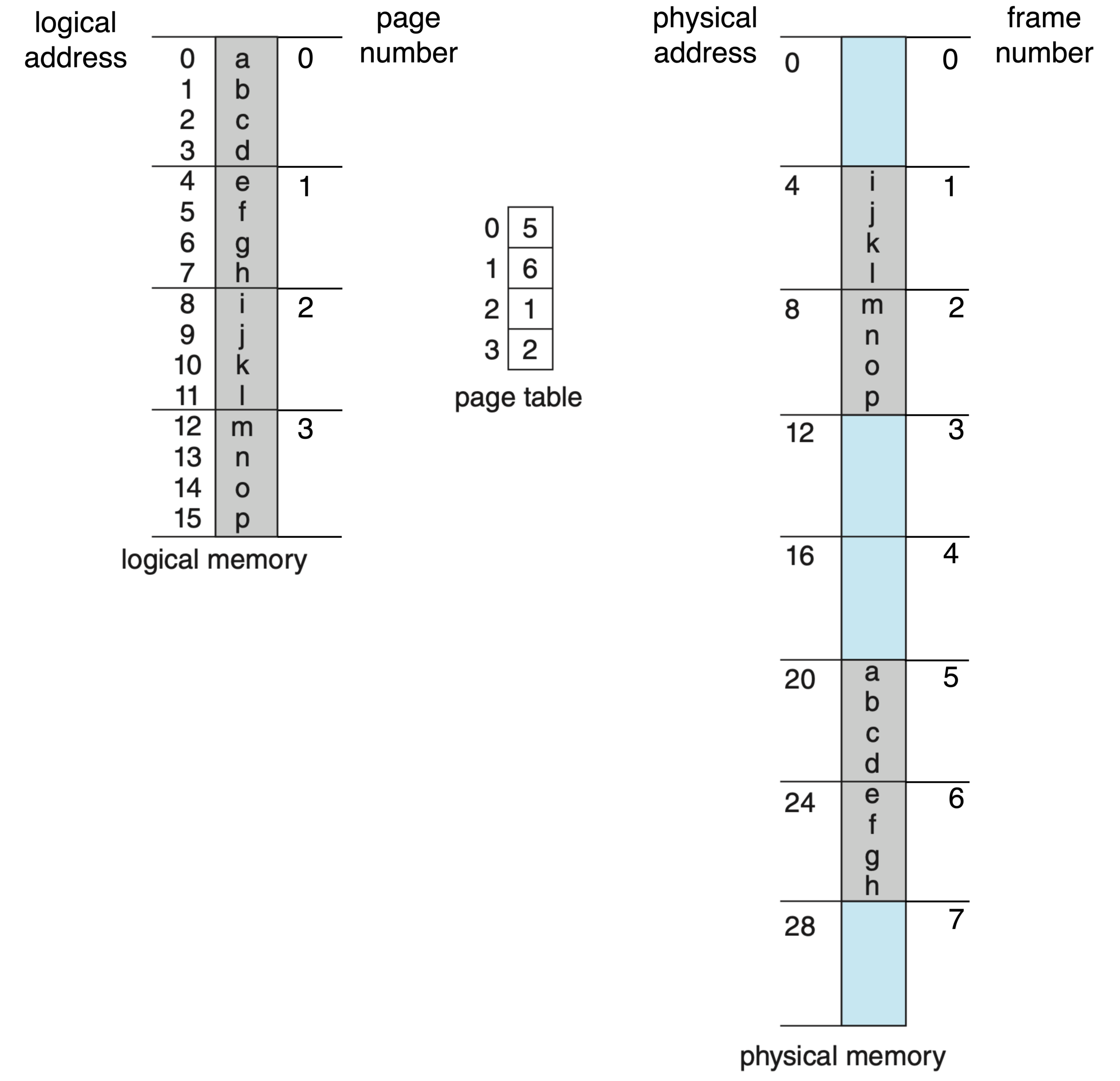
Page Table Variants
- Single-level (flat) page table: One entry per virtual page. Simple, but vast: a 64-bit address space would need an absurdly large table. Impractical on modern systems.
- Hierarchical (multi-level) page tables: The address is split into multiple indices into successive table levels (x86-64 uses four levels by default; recent CPUs support five). Sparse address spaces only allocate the levels they need.
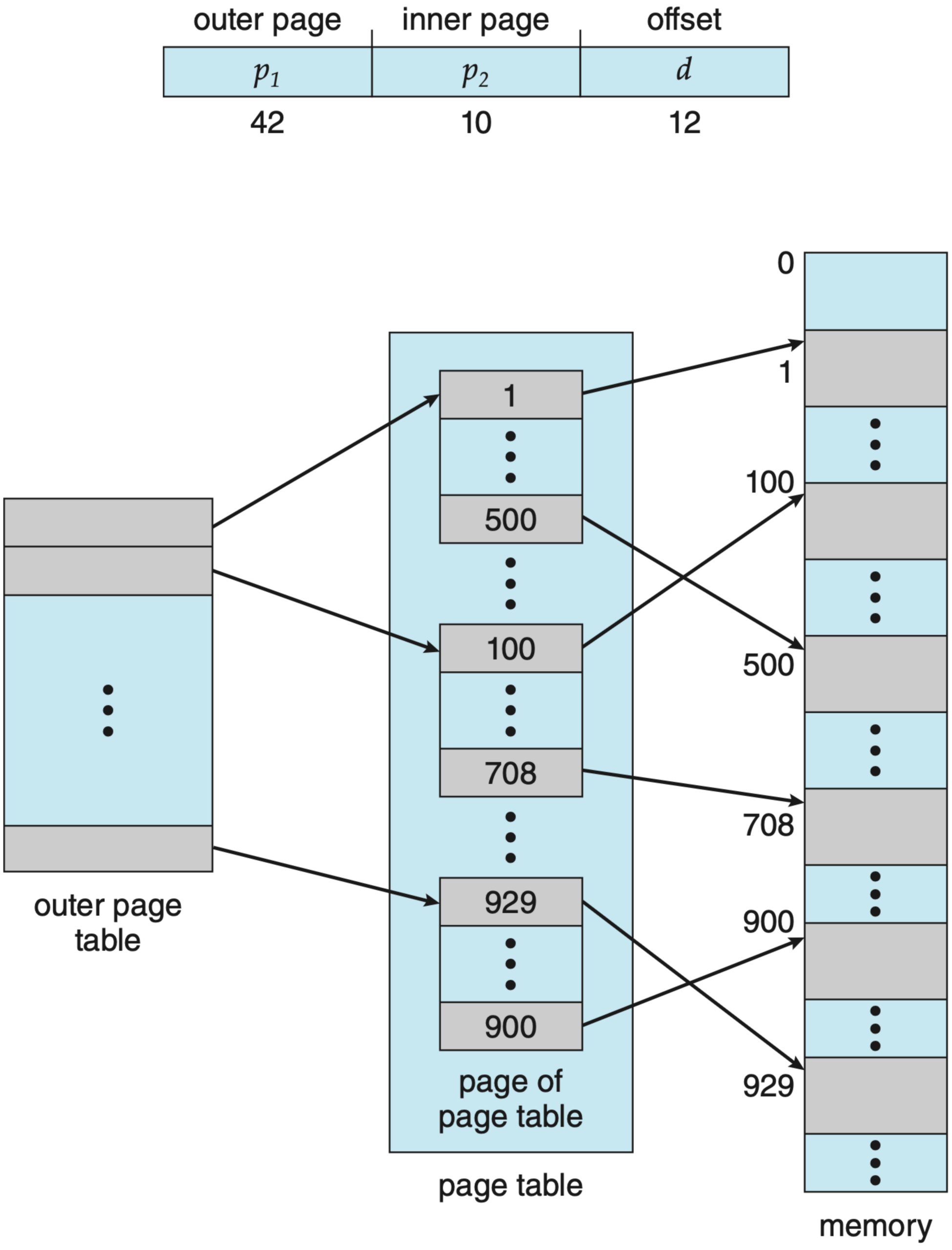
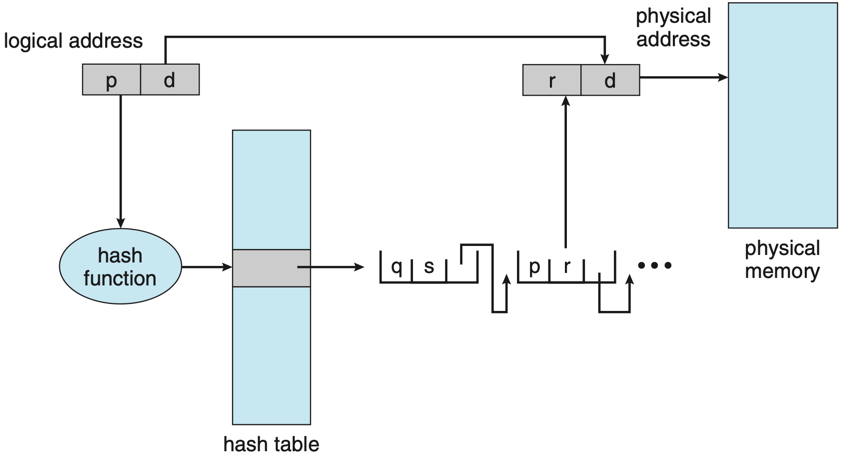
- Hashed page tables: The virtual page number is hashed into a bucket containing the actual mapping. Useful on architectures with very large address spaces.
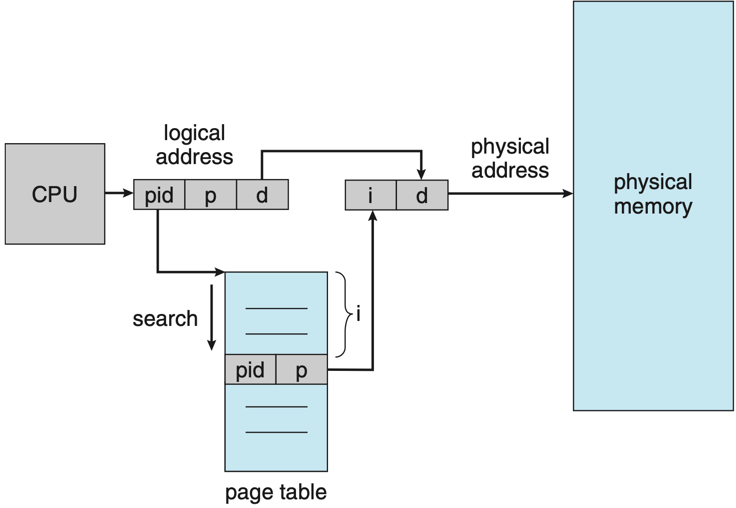
- Inverted page tables: One global entry per physical frame, rather than per virtual page. Saves space at the cost of more expensive lookups.
Demand Paging: Lazy Loading the Address Space
Loading an entire program into physical memory at start-up wastes time and RAM. Demand paging only loads pages when they are actually accessed. Each page-table entry carries a valid/invalid (or “present”) bit; when a process touches a page whose bit is clear, the MMU raises a page fault. The kernel then:
- Decides whether the access is legal (e.g., is it within a mapped region?).
- Finds a free physical frame, or evicts one to swap.
- If the page comes from a file (executable, mmap’d file, swap), reads it from disk into the frame.
- Updates the page-table entry to point at the frame and marks it present.
- Restarts the faulting instruction transparently to the program.
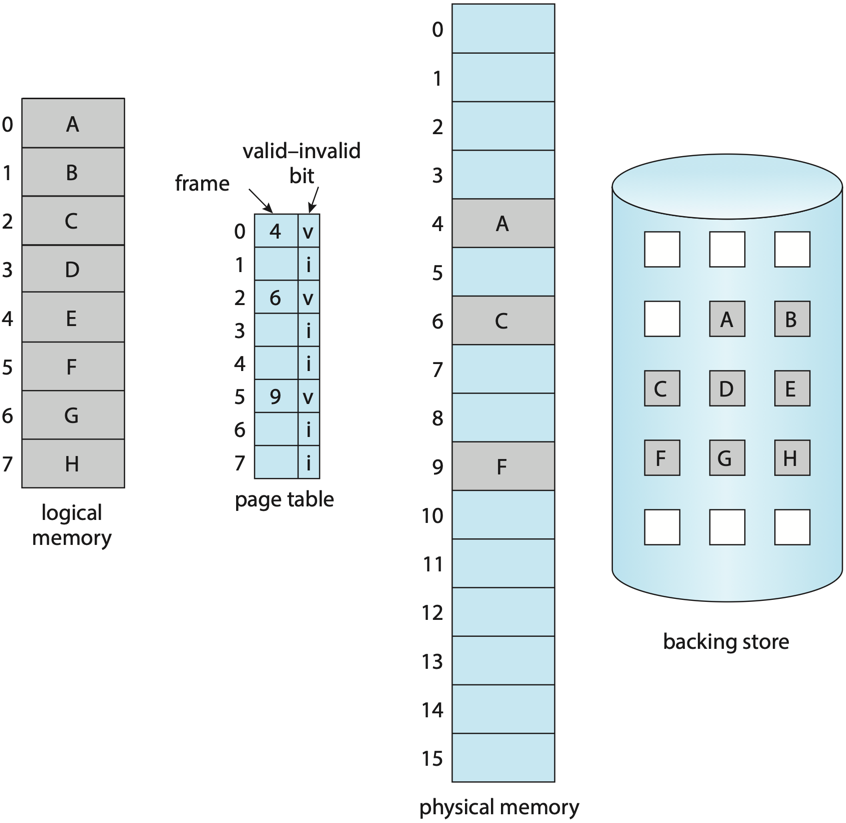
This is why programs start fast and grow into memory over time, and why two distinct virtual-memory metrics matter: VSZ (virtual size — the total address space the process has reserved) and RSS (resident set size — the part actually backed by physical RAM right now).
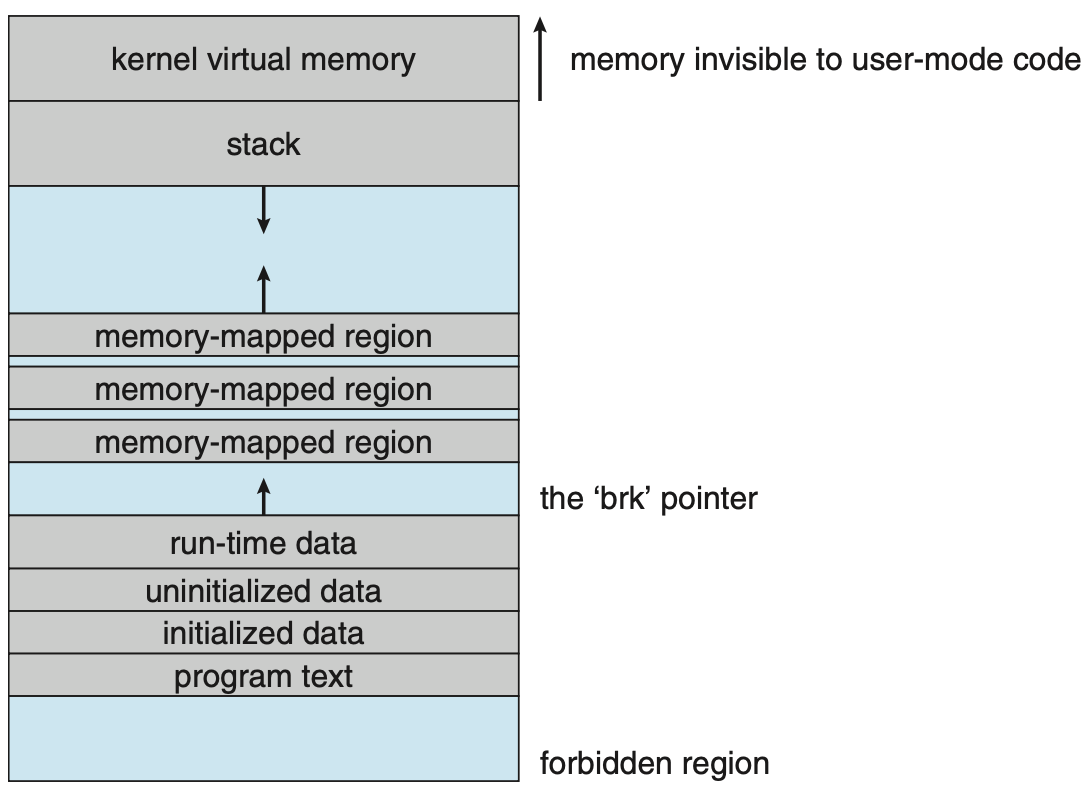
Anatomy of a Process Address Space
A typical x86-64 Linux process address space, viewed from high to low addresses:
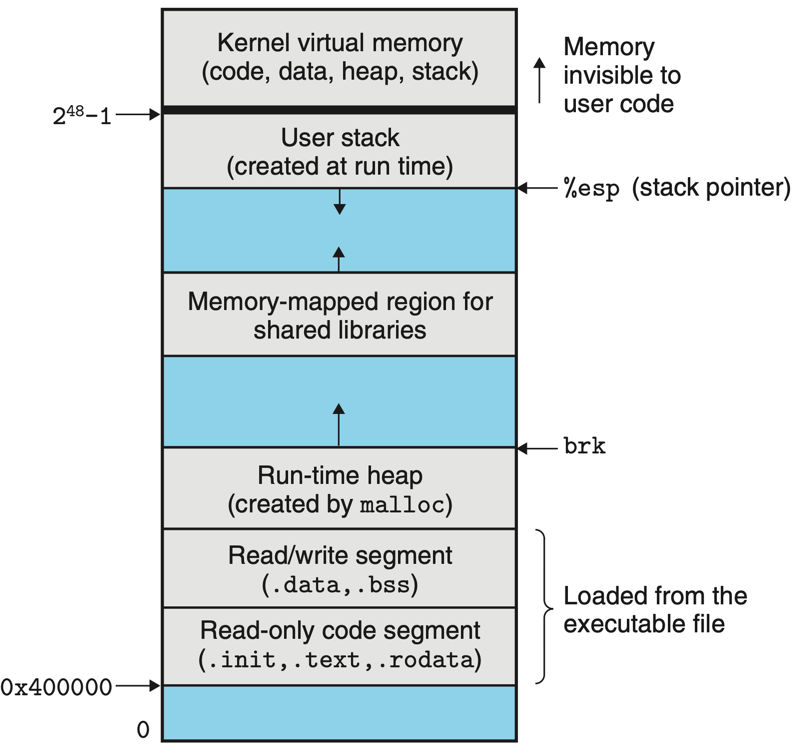
- Kernel space — top half of the address space; not accessible from userland.
- Stack — grows downward from a high address. One stack per thread.
- Memory-mapped region (mmap area) — shared libraries, anonymous mappings, file mappings; grows downward toward the heap.
- Heap — dynamic allocations; grows upward from the end of the BSS via
brk/sbrk. - BSS — uninitialised globals/statics; zero-filled on first access.
- Data — initialised globals/statics; copied from the binary at load time.
- Text — read-only executable code segment.
ASLR randomises the base addresses of stack, heap, mmap region, and (with PIE) text — making it harder for an attacker to predict where to point a control-flow hijack. None of this would be possible without virtual memory.
How the Stack Works
Each thread gets its own stack — created with a default size (commonly 8 MiB on Linux, controlled by RLIMIT_STACK) via clone(2)/pthread_create(3). The CPU maintains a stack pointer (RSP on x86-64) and optionally a base pointer (RBP), which together delimit the current function’s stack frame. Each function call pushes a new frame containing return address, saved registers, and locals; each return pops one.
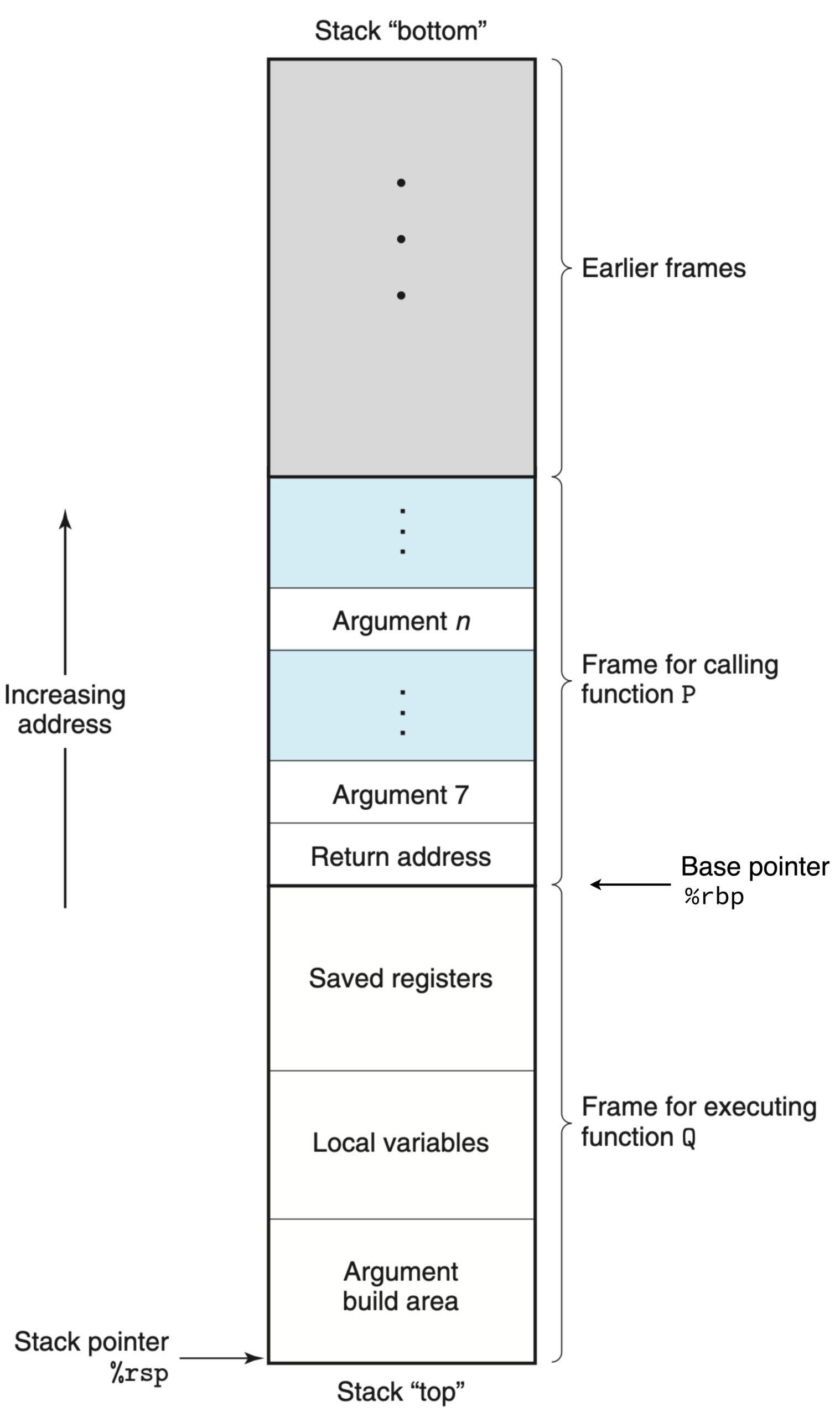
The stack is fast because every “allocation” is just a subtraction from RSP. It is also bounded — deep or unbounded recursion blows past RLIMIT_STACK and triggers a fault.
Where Does the Stack Live in Go?
The original article uses a small Go example to make a subtle point: the compiler decides where locals live based on escape analysis.
package main
func main() {
x := 0
println(&x)
}Taking the address of x can force it to escape to the heap, depending on how it is used. This is one of the practical consequences of understanding stack vs. heap allocation at the language-runtime level.
How the Heap Works
The heap is grown via the brk/sbrk system calls, which move the program break — the boundary between the BSS and the unmapped region above it. Modern allocators (glibc malloc, jemalloc, mimalloc, tcmalloc) usually combine brk for small allocations and mmap for large ones.
Inside that allocator, free memory is tracked in free lists of variable-sized blocks. malloc finds a suitable block (best-fit, first-fit, or a size-class lookup, depending on the allocator), and free returns the block to the list, coalescing with neighbours when possible. The same fragmentation problems that motivated paging show up here at the allocator level, which is why allocator design is an entire subfield.
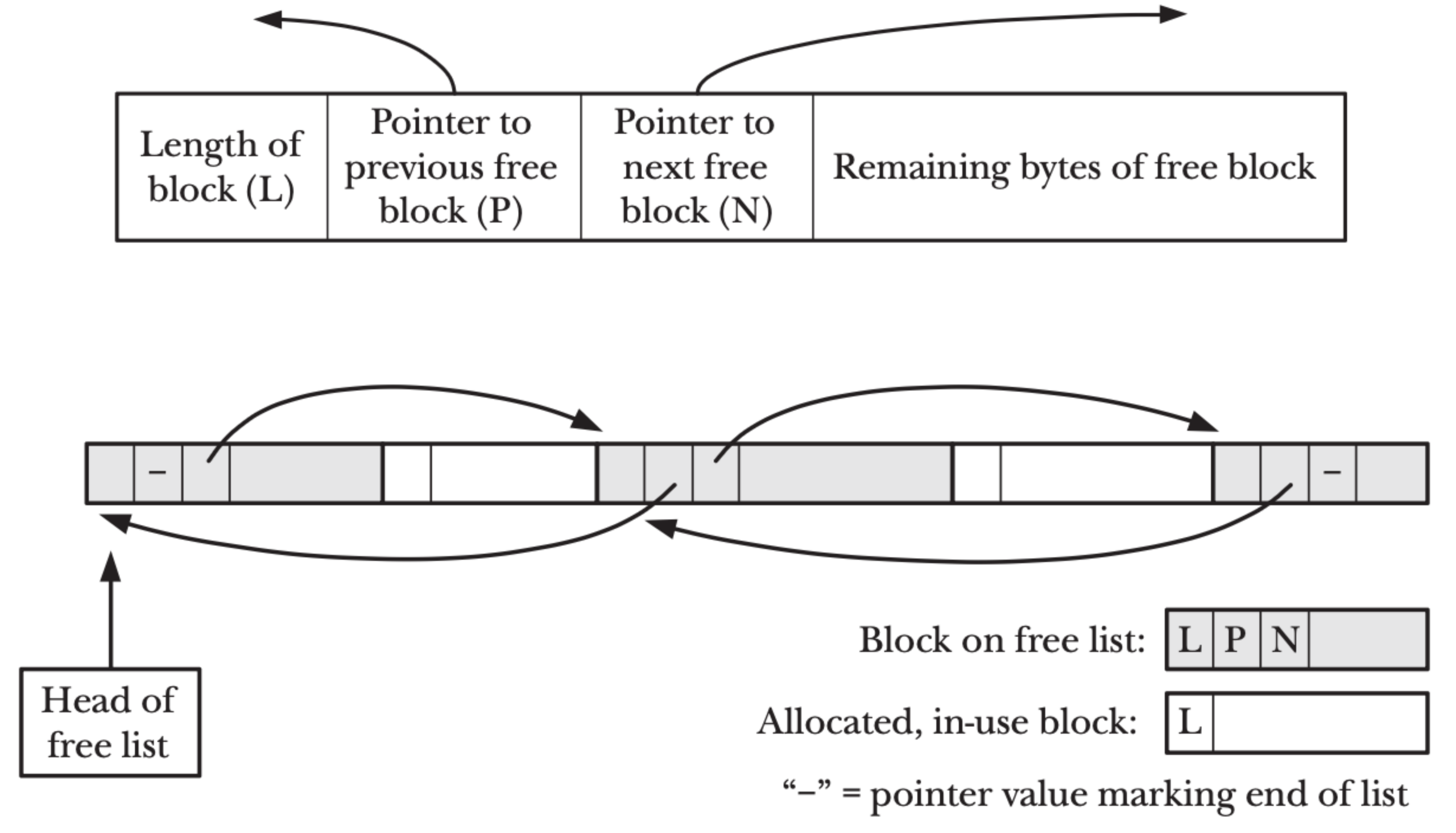
malloc/free track variable-sized blocks. Source: original article.Memory Mapping (mmap) and Copy-on-Write
mmap(2) attaches a region of the virtual address space to a backing source:
- File-backed mappings bind virtual pages to file contents. Reads and writes go through the page cache; faulting in a page is a disk read.
- Anonymous mappings have no backing file. They are zero-filled on first access. This is how the heap (for large allocations) and thread stacks are implemented.
- Shared vs. private: Shared mappings propagate writes back to the file or other mappers; private mappings keep changes local to the process.
Copy-on-write (COW) is the trick that makes fork(2) cheap. The child’s address space is initially a duplicate of the parent’s page tables, with every writable page marked read-only. The first write triggers a page fault, the kernel copies the page, marks the new copy writable in the child, and resumes execution. Pages that are never modified are shared forever. The same mechanism backs private file mappings.
Why Security Engineers Care
Virtually every exploit mitigation and exploitation technique on modern systems is a story about page table entries:
- NX / DEP: the no-execute bit in the PTE makes data pages non-executable, breaking classic stack/heap shellcode.
- W^X: a page is never simultaneously writable and executable, forcing attackers toward ROP/JOP.
- ASLR / KASLR: randomised mappings turn “jump to address X” into a guessing game.
- SMEP / SMAP: CPU features that prevent the kernel from accidentally executing or accessing user pages.
- Page-table isolation (KPTI / Meltdown): partly separating kernel and user page tables to mitigate side-channel reads.
- Heap exploitation: entire classes of bugs (use-after-free, double-free, heap overflows) only make sense in the context of how an allocator interacts with mmap’d arenas.
Key Takeaways
- Virtual memory exists primarily to give processes isolation, protection, and a uniform address space — not just to “use more RAM than you have”.
- Paging eliminates external fragmentation by removing the requirement that a process’s memory be physically contiguous.
- Modern systems use hierarchical page tables indexed by the MMU, with the TLB caching translations for speed.
- Demand paging defers loading until access, which is why VSZ >> RSS for most real programs.
- Each process’s address space follows a predictable layout (kernel, stack, mmap, heap, BSS, data, text), perturbed by ASLR for security.
- The stack is a CPU-managed contiguous region with a hard size limit; the heap is allocator-managed and grown via
brk/mmap. mmap+ copy-on-write underpinfork, shared libraries, and many high-performance I/O patterns.
Defensive Recommendations
- Build PIE binaries. Without position-independent executables, ASLR does not fully randomise the text segment.
- Compile with NX/DEP and W^X. Verify
readelf -lshows aGNU_STACKsegment without the executable flag. - Use hardened allocators (glibc with
MALLOC_CHECK_, jemalloc, scudo, hardened_malloc) where the threat model warrants it. - Audit
mmapusage in code reviews, especiallyPROT_EXECcombined withPROT_WRITE— a common mistake in JIT engines and embedded interpreters. - Enable KPTI/SMEP/SMAP on Linux kernels; verify with
dmesg | grep -E 'KPTI|SMEP|SMAP'. - Treat
brkheap pointers andmmapbase as secrets in any attack surface that exposes them via diagnostic logs, crash dumps, or error pages.
Conclusion
Virtual memory is one of those topics whose abstraction is so successful that most developers can ignore it for years. But every performance pathology you can’t explain, every weird memory-related bug, every modern exploit mitigation, and every clever zero-copy trick ultimately reduces to the contents of a page-table entry. Time spent here pays back in every layer of the stack above it.
Full credit for the original framing of this material and all diagrams goes to the author of “Fundamental of Virtual Memory” on the Melatoni blog. The article on this site is an original rewrite for an English security-engineering audience; diagrams are reproduced from the source with attribution.