
Executive Summary
Lifting x86 machine code into a higher-level intermediate representation is the foundation of most modern static deobfuscators, devirtualizers, and binary translators — but the existing tooling (Remill, Rellume, revng, Triton, angr) is notoriously hard to build, hard to read, and hard to learn from. In a new post on secret club, mrexodia publishes Striga: a ~500-line Python lifter that translates x86_64 instructions into LLVM IR using Capstone for disassembly and a fresh set of Python bindings for LLVM. The architecture borrows the cleanest ideas from Remill (a memory State struct, instructions as basic blocks, intrinsics for control flow) and discards everything that made Remill itself painful to compile.
The post walks the reader through every layer of that lifter — the State structure modelling the CPU, the Semantics class wrapping LLVM’s IR builder, the BFS that recovers basic-block control flow, the per-instruction semantic handlers (mov, and/or/xor, conditional jumps, call, ret), and the “brightening” pipeline that turns lifted IR back into a normal-looking optimised function for the host calling convention. By the end, a 6-line x86 prologue/epilogue (push rbp / mov rbp, rsp / ... / pop rbp / ret) round-trips through Striga and the LLVM default<O1> pipeline as a single-line ret i64 %0. This is the most accessible introduction to LLVM-IR lifting published in some time, and an excellent starting point for anyone interested in static deobfuscation.
Background
mrexodia opens with the motivation: while discussing how to lift BinaryShield to LLVM IR with eversinc33, the obvious move was to write a small Python lifter that turns x86_64 instructions directly into LLVM IR. The post assumes basic familiarity with the structure of LLVM IR.
The wider observation is that newcomers to lifters get stuck on tooling. To clear that runway, the author spent roughly a month in October 2025 reworking Remill’s build system (remill#723) and earlier the same month did the equivalent on the Dna#9 project. Last year the author also started a fresh set of Python bindings for LLVM — Striga is the first real project that uses them. The lifter lives at LLVMParty/striga.
The stated goal is to lower the barrier of entry — the lifter is intentionally small, intentionally readable, and intentionally not production-ready. For prior art, the author points to Back Engineering Labs’ Static Devirtualization of Themida and the Pushan: Trace-Free Deobfuscation of Virtualization-Obfuscated Binaries paper from ASU (March 2026).
What “Lifting” Actually Means
Lifting is the translation of machine instructions into an intermediate representation. The motivation is straightforward: poking at x86 directly is verbose, mistake-prone and full of architectural side-effects (flags, segment overrides, sub-register aliasing). An IR strips those mechanics down to their underlying semantics so program analyses can reason about meaning instead of encoding.
The post enumerates the most common IRs in the wild:
- SMT-LIB — used by Triton for symbolic execution.
- VEX — used by angr (via pyvex).
- Miasm IR.
- Sleigh — used by Ghidra, Remill and Icicle.
- LLVM IR — used by Rellume, revng and Remill.
- Microcode — IDA’s proprietary IR.
- BNIL — Binary Ninja’s proprietary IR.
Striga targets LLVM IR. The author’s justification is pragmatic: the ecosystem is already huge, the optimisation passes are already written, and large compiler teams keep them maintained. Anything an analysis pipeline wants to do after lifting — dead-store elimination, mem2reg, value propagation, constant folding — comes for free from opt.
Architecture: a CPU as an LLVM Struct
The architecture borrows heavily from Remill but trims everything not strictly needed. The central trick is that LLVM IR registers are SSA values — assignable exactly once — while CPU registers are mutable. The standard workaround is to model CPU registers as members of an in-memory State structure, then let LLVM’s mem2reg pass turn the loads and stores back into proper SSA after lifting:
struct State {
uint64_t rax;
uint64_t rbx;
uint64_t rcx;
uint64_t rdx;
// ... GPRs
uint8_t cf;
uint8_t zf;
uint8_t of;
// ... Flags
// ... XMM
};One detail worth highlighting: flags are modelled as independent uint8_t registers rather than packed bits inside RFLAGS. This makes flag updates easier for the optimiser to track and dead-store-eliminate. A separate opaque memory pointer is passed alongside state so the lifter can distinguish “load/store of a CPU register” from “load/store of x86 memory”. The lifted function prototype is therefore void lifted(State* state, void* memory); brightening (later in the post) turns that wrapper into a normal function for the target calling convention.
Here is the LLVM IR emitted for the trivial mov rax, rcx, with the relevant pseudo-C transliterated as comments:
define internal void @lifted_0x140001000(ptr %state, ptr %memory) {
initialize:
; uint64_t* rcx = &state->rcx;
%rcx = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 2
; uint64_t* rax = &state->rax;
%rax = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 0
; Jump to the first instruction
br label %insn_0x140001000
insn_0x140001000: ; preds = %initialize
; uint64_t v0 = *rcx;
%0 = load i64, ptr %rcx, align 4
; *rax = v0;
store i64 %0, ptr %rax, align 4
; Jump to the next instruction
br label %insn_0x140001003
insn_0x140001003: ; preds = %insn_0x140001000
; Block terminator to keep the IR valid
ret void
}The initialize block grabs pointers into the State’s relevant members. Every lifted instruction then occupies its own basic block named insn_<addr>, and is responsible for emitting an unconditional branch to its successor. Each successor block is pre-created with just a ret void terminator so the module verifier never sees an empty block.
Memory accesses follow exactly the same shape. Here is mov rax, qword [rbx+42]:
define internal void @lifted_0x140001000(ptr %state, ptr %memory) {
initialize:
%rbx = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 1
%rax = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 0
br label %insn_0x140001000
insn_0x140001000: ; preds = %initialize
; uint64_t v0 = *rbx;
%0 = load i64, ptr %rbx, align 4
; uint64_t v1 = v0 + 42;
%1 = add i64 %0, 42
; uint8_t* v2 = &memory[v1];
%2 = getelementptr i8, ptr %memory, i64 %1
; uint64_t v3 = *(uint64_t*)v2;
%3 = load i64, ptr %2, align 1
; *rax = v3;
store i64 %3, ptr %rax, align 4
br label %insn_0x140001004
insn_0x140001004: ; preds = %insn_0x140001000
ret void
}The getelementptr i8, ptr %memory, i64 %1 idiom is the marker for an x86 memory access — brightening will rewrite those into raw inttoptr later. The lifter itself is contained in a ~500-line Semantics class:
# src/striga/semantics.py
class Semantics:
def __init__(self, module: Module): ...
# Lifting
def begin(self, address: int) -> Function: ...
def get_or_create_block(self, address: int) -> BasicBlock: ...
def lift_bytes(self, address: int, code: bytes) -> list[Successor]: ...
# Semantic helpers
def reg_read(self, name: str) -> Value: ...
def reg_write(self, name: str, value: Value): ...
def mem_read(self, addr: Value, ty: Type) -> Value: ...
def mem_write(self, addr: Value, value: Value): ...
def op_mem(self, op: X86Op) -> Value: ...
def op_read(self, index: int) -> Value: ...
def op_write(self, index: int, value: Value): ...
def flag_read(self, name: str) -> Value: ...
def flag_write(self, name: str, value: Value): ...
# State (simplified)
module: Module
function: Function
ir: Builder
insn: CsInsnThe begin(address) function creates the lifted_<address> function and its initialize block, then branches into the first lifted instruction:
def begin(self, address: int) -> Function:
name = f"lifted_{hex(address)}"
fn = self.module.get_function(name)
if fn is None:
fn = self.module.add_function(name, self.lifted_ty)
fn.param_attributes(0).add("noalias")
fn.param_attributes(1).add("noalias")
state, memory = fn.params
memory.name = "memory"
state.name = "state"
self.function = fn
self.reg_ptrs = {}
self.insn_blocks = {}
entry = fn.append_basic_block("initialize")
assert fn.last_basic_block == entry
with entry.create_builder() as ir:
ir.br(self.get_or_create_block(address))
else:
# Omitted for brevity
return self.functionTo create the per-instruction block, get_or_create_block pre-fills it with a stub ret void so it is verifier-valid even before lifting has happened:
def get_or_create_block(self, address: int) -> BasicBlock:
block = self.insn_blocks.get(address)
if block is None:
block = self.function.append_basic_block(f"insn_{hex(address)}")
with block.create_builder() as ir:
ir.ret_void()
self.insn_blocks[address] = block
assert block.function == self.function
return blocklift_bytes is where the real per-instruction work happens. It looks up the mnemonic in a global handler registry (with a tiny special case to strip a lock prefix and re-dispatch), invokes the handler, and if the handler did not emit a terminator it falls through to the next address:
def lift_bytes(self, address: int, code: bytes) -> list[Successor]:
# Ensure we have a function to lift into
if not hasattr(self, "function"):
self.begin(address)
insn = self.cs_disasm(address, code)
if self.verbose:
print(";", hex(insn.address), insn.mnemonic, insn.op_str)
# Skip lifting if the block is already populated
block = self.get_or_create_block(address)
assert block.first_instruction
if block.first_instruction.opcode == Opcode.Ret:
block.first_instruction.erase_from_parent()
else:
return []
with block.create_builder() as ir:
# State used by semantic handlers
self.ir = ir
self.insn = insn
handler = _semantics.get(insn.mnemonic)
if handler is None and insn.mnemonic.startswith("lock "):
# LOCK preserves the single-threaded architectural result; the
# lifter does not model inter-thread atomicity separately.
handler = _semantics.get(insn.mnemonic.removeprefix("lock "))
if handler is None:
raise NotImplementedError(insn.mnemonic)
successors = handler(self)
if successors is None:
# Linear fallthrough - handler didn't emit a terminator.
fallthrough = address + insn.size
ir.br(self.get_or_create_block(fallthrough))
successors = [Successor(address, self.const64(fallthrough))]
# Make sure the handler produced valid IR
self.module.verify_or_raise()
return successorsThe Successor tuple uses an LLVM Value for the destination instead of a plain integer, so non-constant branches (jmp rax, ret) fit the same shape as jmp imm:
class Successor(NamedTuple):
src: int
dst: ValueHandlers are registered with a small @semantic decorator that strips a trailing underscore from Python keywords like and_ and or_:
# src/striga/semantic.py
SemanticFn: TypeAlias = Callable[["Semantics"], list[Successor] | None]
_semantics: dict[str, SemanticFn] = {}
def semantic(fn: SemanticFn):
name = getattr(fn, "__name__")
_semantics[name.removesuffix("_")] = fn
return fn
# src/striga/x86/data.py
@semantic
def mov(sem: Semantics):
value = sem.op_read(1)
sem.op_write(0, value)The handlers themselves dispatch through a small set of helpers on the Semantics object. op_read handles operand decoding via Capstone:
def op_read(self, index: int) -> Value:
op: X86Op = self.insn.operands[index]
if op.type == CS_OP_REG:
name = self.reg_name(op.reg) # pyright: ignore[reportAssignmentType]
return self.reg_read(name)
if op.type == CS_OP_IMM:
return self.const_n(op.imm, op.size * 8)
if op.type == CS_OP_MEM:
addr = self.op_mem(op)
return self.mem_read(addr, self.types.int_n(op.size * 8))
assert Falsereg_read transparently handles sub-register aliasing (eax, ax, al, ah) by shifting and truncating the parent register’s value — this is the LLVM-IR equivalent of letting the optimiser see the bit layout instead of fighting it:
def reg_read(self, name: str) -> Value:
if name in self.reg_types:
load = self.ir.load(self.reg_types[name], self.reg_ptr(name))
load.metadata["tbaa"] = self.tbaa_tags[name]
return load
full_name, size, bit_offset = self.subregs[name]
load = self.ir.load(self.reg_types[full_name], self.reg_ptr(full_name))
load.metadata["tbaa"] = self.tbaa_tags[full_name]
if bit_offset:
load = self.ir.lshr(load, self.const64(bit_offset))
return self.ir.trunc(load, self.types.int_n(size))The reg_ptr helper memoises the getelementptr for each touched register so the same pointer is reused throughout the function:
def reg_ptr(self, name: str) -> Value:
reg_ptr = self.reg_ptrs.get(name)
if reg_ptr is not None:
return reg_ptr
entry = self.function.entry_block
state = self.function.get_param(0)
with entry.create_builder() as ir:
ir.position_before(entry.terminator)
reg_ptr = ir.struct_gep(self.state_ty, state, self.reg_indices[name], name)
self.reg_ptrs[name] = reg_ptr
return reg_ptrOne nice touch: TBAA metadata is attached to every register load/store so the optimiser knows distinct registers never alias each other. That single line of metadata unlocks much more aggressive dead-store elimination on sequences of lifted instructions.
Semantics: Flags, Logical Ops, and the Undef-AF Intrinsic
Once the structural pieces are in place, individual instructions become readable. Logical binops (and, or, xor) share their entire body except for the LLVM Opcode:
# src/striga/x86/bitwise.py
def write_logical_flags(sem: Semantics, result: Value):
false = sem.const_n(0, 1)
sem.flag_write("cf", false)
sem.flag_write("pf", sem.result_parity_even(result))
sem.flag_write_undef("af")
sem.flag_write("zf", sem.result_is_zero(result))
sem.flag_write("sf", sem.result_sign_bit(result))
sem.flag_write("of", false)
def logical_binop(sem: Semantics, opcode: Opcode):
dst = sem.op_read(0)
src = sem.resize_int(sem.op_read(1), dst.type)
result = sem.ir.binop(opcode, dst, src)
sem.op_write(0, result)
write_logical_flags(sem, result)
@semantic
def and_(sem: Semantics):
logical_binop(sem, Opcode.And)
@semantic
def or_(sem: Semantics):
logical_binop(sem, Opcode.Or)
@semantic
def xor(sem: Semantics):
logical_binop(sem, Opcode.Xor)For reference, this is the LLVM IR Striga emits for xor rax, rbx, with the Python responsible for each chunk in the comments:
insn_0x140001000: ; preds = %initialize
; dst = sem.reg_read(0)
%0 = load i64, ptr %rax, align 4
; src = sem.resize_int(sem.op_read(1), dst.type)
%1 = load i64, ptr %rbx, align 4
; result = sem.ir.binop(Opcode.Xor, dst, src)
%2 = xor i64 %0, %1
; sem.op_write(0, result)
store i64 %2, ptr %rax, align 4
; sem.flag_write("cf", false)
store i8 0, ptr %cf, align 1
; sem.flag_write("pf", sem.result_parity_even(result))
%3 = trunc i64 %2 to i8
%4 = lshr i8 %3, 4
%5 = xor i8 %3, %4
%6 = lshr i8 %5, 2
%7 = xor i8 %5, %6
%8 = lshr i8 %7, 1
%9 = xor i8 %7, %8
%10 = and i8 %9, 1
%11 = icmp eq i8 %10, 0
%12 = zext i1 %11 to i8
store i8 %12, ptr %pf, align 1
; sem.flag_write_undef("af")
%13 = call i1 @__striga_undef_af(i64 5368713216)
%14 = zext i1 %13 to i8
store i8 %14, ptr %af, align 1
; sem.flag_write("zf", sem.result_is_zero(result))
%15 = icmp eq i64 %2, 0
%16 = zext i1 %15 to i8
store i8 %16, ptr %zf, align 1
; sem.flag_write("sf", sem.result_sign_bit(result))
%17 = lshr i64 %2, 63
%18 = trunc i64 %17 to i1
%19 = zext i1 %18 to i8
store i8 %19, ptr %sf, align 1
; sem.flag_write("of", false)
store i8 0, ptr %of, align 1
; Semantics.lift_bytes
br label %insn_0x140001003The interesting line is call i1 @__striga_undef_af. AF (the auxiliary carry flag) is documented by Intel and AMD as undefined after xor. From the Intel manual entry for XOR:
The OF and CF flags are cleared; the SF, ZF, and PF flags are set according to the result. The state of the AF flag is undefined.
Intel Software Developer’s Manual —XORentry
In practice “undefined” means the silicon answer can vary between CPU generations and that anti-emulation code does sometimes use this. Striga represents the unknown as an opaque intrinsic call (__striga_undef_af) and leaves it to the downstream analysis to decide what to model. The author points to remill#766 for the broader design discussion.
Control-flow instructions are the other class worth highlighting:
# src/striga/x86/control.py
def conditional_jump(sem: Semantics, cond: Value):
brtrue = sem.insn.operands[0].imm
brfalse = sem.insn.address + sem.insn.size
sem.ir.cond_br(
cond,
sem.get_or_create_block(brtrue),
sem.get_or_create_block(brfalse),
)
src = sem.insn.address
return [
Successor(src, sem.const64(brtrue)),
Successor(src, sem.const64(brfalse)),
]
def jcc(sem: Semantics, cc: str):
return conditional_jump(sem, cc_cond(sem, cc))
@semantic
def je(sem: Semantics):
return jcc(sem, "e")
@semantic
def jmp(sem: Semantics):
dst = sem.op_read(0)
if dst.is_constant:
sem.ir.br(sem.get_or_create_block(dst.const_zext_value))
else:
sem.ir.call(sem.jmp_handler, [dst])
sem.ir.ret_void()
return [Successor(sem.insn.address, dst)]
@semantic
def call(sem: Semantics):
dst = sem.op_read(0)
fallthrough = sem.insn.address + sem.insn.size
sem.push(sem.const64(fallthrough))
sem.ir.call(sem.call_handler, [dst])
sem.ir.br(sem.get_or_create_block(fallthrough))
return [Successor(sem.insn.address, sem.const64(fallthrough))]
@semantic
def ret(sem: Semantics):
dst = sem.pop(sem.i64)
if sem.insn.operands:
rsp = sem.reg_read("rsp")
sem.reg_write("rsp", sem.ir.add(rsp, sem.const64(sem.insn.operands[0].imm)))
sem.ir.call(sem.ret_handler, [dst])
sem.ir.ret_void()
return [Successor(sem.insn.address, dst)]The semantic handler for jcc is responsible for emitting both successor blocks and the br with the appropriate flag-derived condition. jmp takes either a constant (folded to a static br) or a non-constant (lowered to an opaque __striga_jmp intrinsic). call and ret are similarly modelled as __striga_call / __striga_ret intrinsics so the downstream analysis can choose its own calling convention.
For reference, the IR shapes for each:
LLVM IR for je imm:
insn_0x140001000: ; preds = %initialize
%0 = load i8, ptr %zf, align 1
%1 = icmp ne i8 %0, 0
br i1 %1, label %insn_0x140001014, label %insn_0x140001002
insn_0x140001014: ; preds = %insn_0x140001000
ret void
insn_0x140001002: ; preds = %insn_0x140001000
ret void
}LLVM IR for jmp rbx:
insn_0x140001000: ; preds = %initialize
%0 = load i64, ptr %rbx, align 4
call void @__striga_jmp(i64 %0)
ret voidLLVM IR for call imm:
insn_0x140001000: ; preds = %initialize
%0 = load i64, ptr %rsp, align 4
%1 = sub i64 %0, 8
store i64 %1, ptr %rsp, align 4
%2 = getelementptr i8, ptr %memory, i64 %1
store i64 5368713221, ptr %2, align 1
call void @__striga_call(i64 5369761797)
br label %insn_0x140001005LLVM IR for ret:
insn_0x140001000: ; preds = %initialize
%0 = load i64, ptr %rsp, align 4
%1 = getelementptr i8, ptr %memory, i64 %0
%2 = load i64, ptr %1, align 1
%3 = add i64 %0, 8
store i64 %3, ptr %rsp, align 4
call void @__striga_ret(i64 %2)
ret void
}So three intrinsics carry the analysis hooks: __striga_jmp for indirect jumps, __striga_call for function calls, and __striga_ret for returns. Each one is a single instruction in the lifted IR that an external pass can pattern-match and rewrite.
Control-Flow Recovery
Because every instruction is its own basic block, control-flow recovery becomes a small BFS over the worklist of successors. There is nothing special-cased about loops or block-splitting — lifted instructions are already “islands” that branch into each other arbitrarily:
def lift(module: Module, container: Container, start: int, *, verbose=True):
sem = Semantics(module, verbose=verbose)
lifted_fn = sem.begin(start)
queue: Queue[Successor] = Queue()
queue.put(Successor(0, sem.const64(start)))
# Keep destinations as LLVM Values instead of splitting constants into ints.
# This keeps the worklist uniform and matches later slicing/data-flow uses.
visited: set[Value] = set()
while not queue.empty():
src, dst = queue.get()
if not dst.is_constant:
if sem.verbose:
print(f"; non-constant branch destination: {hex(src)} -> {dst}")
continue
if dst in visited:
continue
visited.add(dst)
va = dst.const_zext_value
code = container.get_data(va, 15)
successors = sem.lift_bytes(va, code)
for successor in successors:
if successor.dst in visited:
continue
queue.put(successor)
sem.module.verify_or_raise()
return lifted_fnTo make the result concrete, the post lifts this small assembly snippet (an if/else followed by a loop):
test_cfg:
cmp rax, 0
je .else_block
.if_true:
add rax, 1
jmp .merge
.else_block:
add rax, 2
.merge:
sub rax, 1
jne .merge
.exit:
retThe graph of the disassembly is shown below:
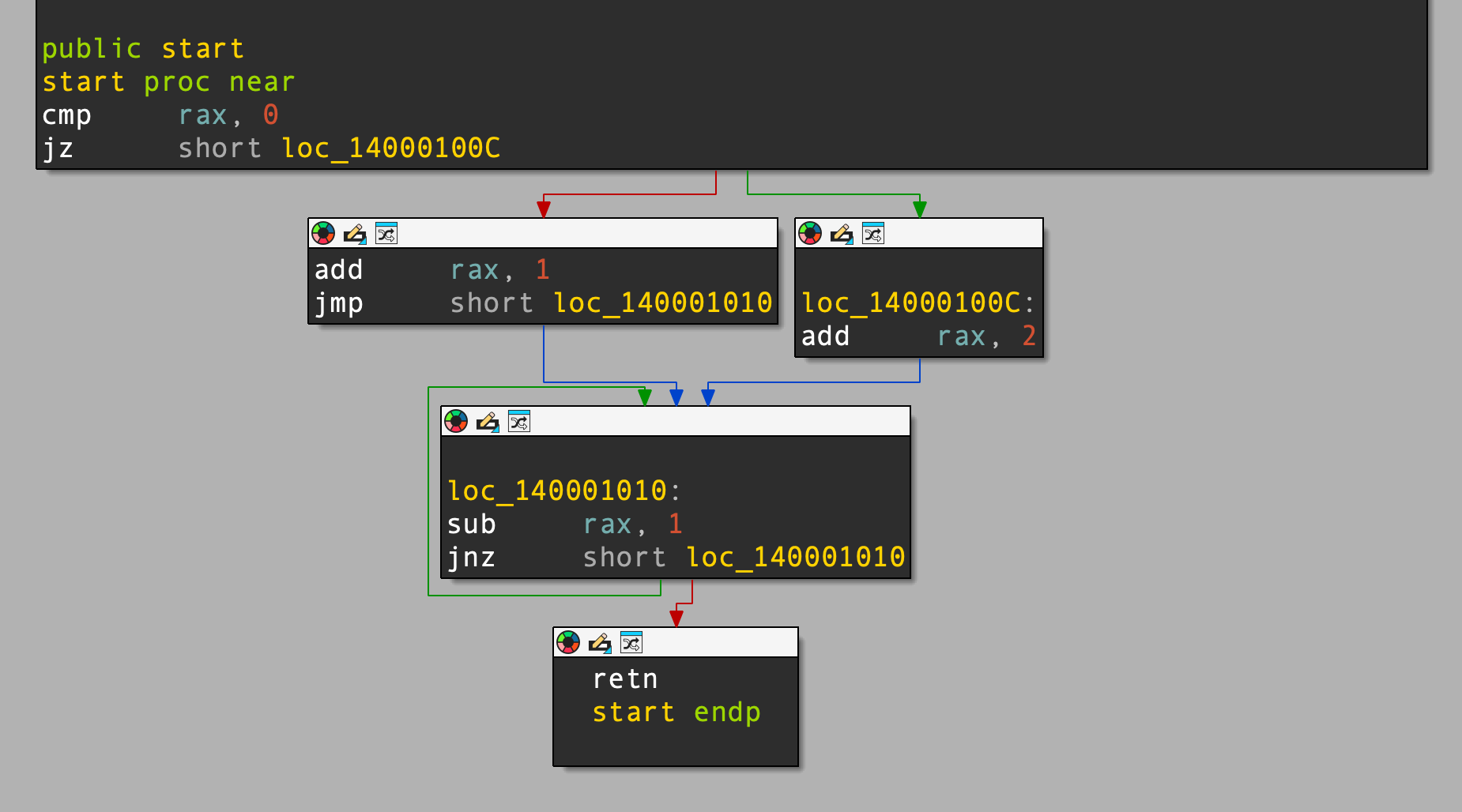
test_cfg sample. Source: original article.And the corresponding LLVM IR Striga emits (with some flag computations elided for clarity):
define internal void @lifted_0x140001000(ptr %state, ptr %memory) {
initialize:
%rax = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 0
%zf = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 51
%rsp = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 6
br label %insn_0x140001000
insn_0x140001000: ; preds = %initialize
; cmp rax, 0
%0 = load i64, ptr %rax, align 4
%1 = sub i64 %0, 0
%19 = icmp eq i64 %1, 0
%20 = zext i1 %19 to i8
store i8 %20, ptr %zf, align 1
br label %insn_0x140001004
insn_0x140001004: ; preds = %insn_0x140001000
; je 0x14000100c
%30 = load i8, ptr %zf, align 1
%31 = icmp ne i8 %30, 0
br i1 %31, label %insn_0x14000100c, label %insn_0x140001006
insn_0x14000100c: ; preds = %insn_0x140001004
; add rax, 2
%32 = load i64, ptr %rax, align 4
%33 = add i64 %32, 2
store i64 %33, ptr %rax, align 4
br label %insn_0x140001010
insn_0x140001006: ; preds = %insn_0x140001004
; add rax, 1
%62 = load i64, ptr %rax, align 4
%63 = add i64 %62, 1
store i64 %63, ptr %rax, align 4
br label %insn_0x14000100a
insn_0x140001010: ; preds = %insn_0x140001014, %insn_0x14000100a, %insn_0x14000100c
; sub rax, 1
%92 = load i64, ptr %rax, align 4
%93 = sub i64 %92, 1
store i64 %93, ptr %rax, align 4
%111 = icmp eq i64 %93, 0
%112 = zext i1 %111 to i8
store i8 %112, ptr %zf, align 1
br label %insn_0x140001014
insn_0x14000100a: ; preds = %insn_0x140001006
; jmp 0x140001010
br label %insn_0x140001010
insn_0x140001014: ; preds = %insn_0x140001010
; jne 0x140001010
%122 = load i8, ptr %zf, align 1
%123 = icmp ne i8 %122, 0
%124 = xor i1 %123, true
br i1 %124, label %insn_0x140001010, label %insn_0x140001016
insn_0x140001016: ; preds = %insn_0x140001014
; ret
%125 = load i64, ptr %rsp, align 4
%126 = getelementptr i8, ptr %memory, i64 %125
%127 = load i64, ptr %126, align 1
%128 = add i64 %125, 8
store i64 %128, ptr %rsp, align 4
call void @__striga_ret(i64 %127)
ret void
}The back-edge from insn_0x140001014 into insn_0x140001010 is just another br; nothing special is needed to handle loops, and the insn_0x140001010 block already lists three predecessors because both the if branch and the loop tail land there.
Brightening: From Lifted to “Normal” Code
The post introduces “brightening” with the SATURN paper’s definition:
Brightening [COMP.] verb — Reshaping code to make it more readable and understandable for humans
Peter Garba and Matteo Favaro, SATURN paper (2019)
Concretely, brightening takes the lifted shape — functions whose state lives in an in-memory State struct — and converts it back to a normal function for the host calling convention. So lifted code that looks like this (pseudo-C):
/*
Lifted instructions:
add rdi, rsi
mov rax, rdi
ret
*/
void lifted(State* state, void* memory) {
state.rdi += state.rsi;
state.rax = state.rdi;
__striga_ret(...);
}Should end up as:
// Linux calling convention: https://wiki.osdev.org/System_V_ABI#x86-64
uint64_t /* rax */ brightened(uint64_t /* rdi */ x, uint64_t /* rsi */ y) {
return x + y;
}The trick is a wrapper function that allocates the State struct, assigns arguments to the correct register slots, calls the lifted function, then returns whatever register the calling convention says the result lives in. Conceptually:
// Symbolic variable for memory
uint8_t RAM[0];
void lifted(State* state, void* memory) { ... }
uint64_t brightened(uint64_t x, uint64_t y) {
State state;
state.rdi = x;
state.rsi = y;
lifted(&state, RAM);
return state.rax;
}After inlining:
uint64_t brightened(uint64_t x, uint64_t y) {
State state;
state.rdi = x;
state.rsi = y;
state.rdi += state.rsi;
state.rax = state.rdi;
__striga_ret(...);
return state.rax;
}And, with the __striga_ret hook removed, the optimiser collapses the whole wrapper to the original shape:
uint64_t brightened(uint64_t x, uint64_t y) {
return x + y;
}In LLVM IR the pre-optimisation wrapper is:
define i64 @brightened_0x1000(i64 %0, i64 %1) {
entry:
%state = alloca %State, align 8
%rdi = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 5
store i64 %0, ptr %rdi, align 4
%rsi = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 4
store i64 %1, ptr %rsi, align 4
%stack = alloca i8, i64 4096, align 1
%2 = getelementptr i8, ptr %stack, i64 4088
%3 = ptrtoint ptr %2 to i64
%rsp = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 6
store i64 %3, ptr %rsp, align 4
store i64 3735928559, ptr %2, align 1
call void @lifted_0x1000(ptr %state, ptr @RAM)
%rax = getelementptr inbounds nuw %State, ptr %state, i32 0, i32 0
%4 = load i64, ptr %rax, align 4
ret i64 %4
}After running the module through default<O1>:
define i64 @brightened_0x1000(i64 %0, i64 %1) {
entry:
%2 = add i64 %1, %0
ret i64 %2
}Memory / Stack
Memory access in the lifted IR routes through a global RAM array passed as the memory parameter. For a function like:
uint64_t lift4_read(uint64_t *n) {
return *n ^ 1337;
}The first-pass brightened IR keeps the “GEP rooted at @RAM” shape:
define i64 @brightened_0x1000(i64 %0) {
entry:
%1 = getelementptr i8, ptr @RAM, i64 %0
%2 = load i64, ptr %1, align 1, !alias.scope !19, !noalias !22
%3 = xor i64 %2, 1337
ret i64 %3
}Striga then sweeps over every user of @RAM and rewrites it to an inttoptr, which lets the function look like normal address-space code:
define i64 @brightened_0x1000(i64 %0) {
entry:
%1 = inttoptr i64 %0 to ptr
%2 = load i64, ptr %1, align 1, !alias.scope !19, !noalias !22
%3 = xor i64 %2, 1337
ret i64 %3
}The stack is modelled by allocating a buffer and pointing rsp at the high end (since x86 stacks grow down):
uint64_t brightened(uint64_t x, uint64_t y) {
uint8_t stack[4096];
State state;
state.rdi = x;
state.rsi = y;
state.rsp = (uint64_t)&stack[sizeof(stack) - 8];
lifted(&state, RAM);
return state.rax;
}All of that is glued together in brighten.py:
from llvm import Linkage, Module, Opcode, Value, global_context
from bfs import lift_bfs
from container import Container, RawContainer
OPT_PIPELINE = "default<O1>"
def rewrite_ram_geps(module: Module, ram: Value):
"""Replace GEPs rooted at @RAM with inttoptr(address)."""
types = module.context.types
for gep in ram.users:
if not gep.is_instruction or gep.opcode != Opcode.GetElementPtr:
raise ValueError(f"unexpected @RAM user: {gep}")
if gep.get_operand(0) != ram:
raise ValueError(f"unexpected @RAM GEP base: {gep}")
if gep.num_operands == 2:
if gep.gep_source_element_type != types.i8:
raise ValueError(f"expected i8 ptradd-style @RAM GEP: {gep}")
address = gep.get_operand(1)
elif gep.num_operands == 3:
zero = gep.get_operand(1)
if not zero.is_constant_int or zero.const_zext_value != 0:
raise ValueError(f"expected zero first @RAM GEP index: {gep}")
address = gep.get_operand(2)
else:
raise ValueError(f"unexpected @RAM GEP shape: {gep}")
with gep.create_builder() as ir:
ptr = ir.inttoptr(address, types.ptr)
gep.replace_all_uses_with(ptr)
gep.erase_from_parent()
if not ram.users:
ram.delete_global()
module.verify_or_raise()
def define_ret_stub(module: Module):
"""Make the modeled return hook removable for this demo wrapper."""
ret_handler = module.get_function("__striga_ret")
if ret_handler is not None and ret_handler.is_declaration:
ret_handler.linkage = Linkage.Internal
entry = ret_handler.append_basic_block("entry")
with entry.create_builder() as ir:
ir.ret_void()
def lift_brightened(container: Container, entry: int, args: list[str]):
with global_context().create_module("blog") as module:
sem = lift_bfs(module, container, entry, verbose=True)
# Convenience aliases
types = module.context.types
i8 = types.i8
i64 = types.i64
# Global RAM array
ram = module.add_global(types.array(i8, 0), "RAM")
# TODO: support different register sizes
brightened_ty = types.function(i64, [i64 for _ in args])
brightened = module.add_function(f"brightened_{hex(entry)}", brightened_ty)
with brightened.create_builder() as ir:
state = ir.alloca(sem.state_ty, "state")
def reg_ptr(name: str) -> Value:
return ir.struct_gep(sem.state_ty, state, sem.reg_indices[name], name)
# Assign arguments to register state
for i, name in enumerate(args):
ir.store(brightened.get_param(i), reg_ptr(name))
# Set up function stack
stack = ir.alloca(i8, i64.constant(4096), "stack")
stack_ptr = ir.gep(i8, stack, [i64.constant(4096 - 8)])
ir.store(ir.ptrtoint(stack_ptr, i64), reg_ptr("rsp"))
# Set up return address
retaddr_store = ir.store(i64.constant(0xDEADBEEF), stack_ptr)
retaddr_store.inst_alignment = 1
# Call lifted function
ir.call(sem.function, [state, ram])
# Load return value from rax and return it
ir.ret(ir.load(i64, reg_ptr("rax")))
module.verify_or_raise()
# 1. Inline/optimize with @RAM assigned to the lifted memory parameter.
module.optimize(OPT_PIPELINE)
# 2. Brighten lifted memory: @RAM + integer address -> inttoptr(address).
rewrite_ram_geps(module, ram)
# 3. Now that RAM accesses have been brightened, discard the modeled ret
# hook for this demo and let LLVM clean up the remaining wrapper noise.
# Undefined flag helpers are already declared memory(none) by Semantics,
# so their dead uses fold away without local stub definitions.
define_ret_stub(module)
module.verify_or_raise()
module.optimize(OPT_PIPELINE)
print(brightened)To demonstrate the end-to-end pipeline, the author lifts a 6-line unoptimised prologue/epilogue:
; 0x1000 push rbp
; 0x1001 mov rbp, rsp
; 0x1004 mov qword ptr [rbp - 8], rdi
; 0x1008 mov rax, qword ptr [rbp - 8]
; 0x100c pop rbp
; 0x100d retAnd out the other side of brightening + default<O1> comes the expected one-liner:
define i64 @brightened_0x1000(i64 returned %0) {
entry:
ret i64 %0
}Key Takeaways
- Striga is a deliberately small (~500-line) Python lifter built on Capstone for disassembly and a new set of Python bindings for LLVM. It is the easiest entry-point published to date for someone who wants to learn LLVM-IR lifting.
- Architecture mirrors Remill, minus the build pain. The CPU is an in-memory
Statestruct; each lifted x86 instruction is its own LLVM basic block; control transfers use__striga_jmp,__striga_call,__striga_retintrinsics so downstream passes can decide how to model them. - Flags as independent
i8registers — not packed bits — massively improves the optimiser’s ability to do dead-store elimination on lifted code. - TBAA metadata +
noaliason the State and memory parameters are the cheap wins that makemem2regand later passes collapse the lifted IR back into something readable. - Brightening — a wrapper function that allocates
State, populates registers per the target calling convention, calls the lifted function and reads back the result register — letsopt -O1reduce a lifted x86 prologue/epilogue to a clean one-line function. - Architecturally undefined behaviour (e.g. AF after
xor) is represented as an opaque intrinsic (__striga_undef_af) instead of being silently faked, which leaves downstream passes free to model it however they want. - No tests, partial x86 coverage, no production claim. The author is explicit that this is a teaching artifact and an experimentation playground, not a deployable analyzer.
Defensive Recommendations
- Assume offensive tooling will get easier, not harder. The barrier to writing a custom LLVM-IR-based deobfuscator just dropped meaningfully. If your protection scheme’s threat model leaned on “nobody will rebuild Remill from source,” revisit it — a researcher can now stand up a usable lifter over a weekend.
- Stress-test code virtualizers against simple lifters first. If a 500-line Python lifter can round-trip your VM’s prologue/epilogue through LLVM’s
default<O1>back to a clean function, your VM is already too transparent. Add semantic noise thatoptcannot fold (calling-convention shuffles, MBA expressions, real undefined-behaviour reads) before relying on the VM as a layer. - Treat the
__striga_undef_afpattern as a defence opportunity. Anti-emulation code that exercises documented-undefined corners (AF semantics, flags aftershlby a non-constant,bsr/bsfon zero) survives generic lifters because they emit opaque intrinsics. Custom analyses that model the wrong silicon answer get caught. - Watch the “global RAM array” pattern in malware unpackers. The same trick Striga uses for brightening — replacing
GEP @RAMwithinttoptr— is how unpackers reconstruct readable address-space code from lifted IR. Detection rules that look for the rewrite of opaque memory globals into typed pointers can flag in-progress unpacks. - Keep your obfuscator’s control flow non-relocatable. Striga’s BFS recovers function CFGs purely from concrete branch destinations. Indirect branches whose destinations depend on a runtime computation that
optcannot constant-fold stay as a single__striga_jmp— the analyst has to walk them by hand. - If you ship a kernel-level protector, model flag side-effects yourself. Anti-emulation tricks that read AF / PF in surprising ways defeat naive lifters but also defeat your own debuggers. Have an internal lifter that matches your protector’s assumptions so the team can analyse customer crashes.
- Train the team on LLVM IR. Whether you are on red or blue, an analyst who can read LLVM IR fluently can use Striga as a microscope on packed/protected code without having to fight a 50 000-line C++ project to do it. The fastest way in is the post’s reading list at the bottom (the “A Gentle Introduction to LLVM IR” series).
Conclusion
Striga is a small lifter with an outsized teaching value. The architecture is deliberately the same as Remill’s — State struct, instructions as blocks, intrinsics for control flow — but the implementation fits in 500 lines of Python, builds without an afternoon of CMake therapy, and produces IR clean enough that opt -O1 can roundtrip a small function back to its source form. If you have ever wanted to experiment with LLVM-based static deobfuscation but bounced off the existing tooling, this is the place to start.
Original text: “Striga: Lifting x86 to LLVM IR with Python” by mrexodia at secret club. Repository at LLVMParty/striga.