Executive Summary
Lu, Zhang, Zhang, Wang, and Guo’s upcoming USENIX Security ’26 paper introduces CuSafe, the first practical memory sanitizer for unmodified, off-the-shelf NVIDIA GPUs that catches both spatial (out-of-bounds) and temporal (use-after-free) memory corruption with low overhead. Modern GPU code — especially PyTorch, TensorFlow and PaddlePaddle backends — is dominated by C/C++ kernels that exhibit exactly the same memory-safety bug classes that have plagued CPU software for decades, and recent work has shown those bugs are exploitable into ROP, ML model corruption, and other primitives on the GPU side. The existing defences either need hardware that doesn’t exist on commodity parts (GPUShield, IMT, LMI, GPUArmor), need NVIDIA’s proprietary toolchain (cuCatch), or are too slow to deploy (compute-sanitizer at ~15× runtime overhead).
CuSafe’s contribution is the engineering combination that gets you to a deployable sanitizer on stock NVIDIA hardware: pointer tagging encoded through the GPU MMU’s page-directory translation; in-band exact buffer bounds prepended to each allocation; stack-epoch tracking and virtual-address randomization to defeat metadata confusion under reallocation; and three LLVM optimization passes that eliminate roughly 20% of redundant checks. The result is implemented as an LLVM 21 transform pass plus a dynamic library hooking cudaMalloc/cudaFree in 2 964 lines of C/C++, achieves 100% coverage on the authors’ 33-program bug suite (15 spatial + 18 temporal cases, the only system in the comparison to score 100% on both), and incurs an average 13% runtime overhead and 0.3% memory overhead across 44 benchmarks — including a measured 11% throughput drop on LLaMA2-7B and LLaMA3-8B inference. The full source is released on figshare.
Why GPU Memory Safety Is Now an Open Problem
GPUs started life as fixed-function rasterisation engines, but CUDA and OpenACC have turned them into general-purpose accelerators that the entire ML, scientific computing and HPC stack now runs on. Almost all of that code is written in C/C++, with all the memory-safety problems that come with it. The PyTorch tracker has accumulated a long tail of GPU-side memory-corruption issues (issues #144611, #145349, #154724 are the ones the paper cites by number), and equivalent bugs show up in TensorFlow (#94118) and PaddlePaddle.
The reason these bugs matter is not just robustness. Guo et al.’s USENIX Security ’24 work (“GPU memory exploitation for fun and profit”) demonstrated that the very same flaws are exploitable into ROP chains running on the GPU. Park et al.’s 2021 “Mind control attack” showed that GPU memory corruption can subvert deep-learning model predictions. Roels et al.’s 2025 EuroSec study found that the basic CPU-side defences — the stack canary in particular — are less secure on GPUs than on CPUs. Whatever your threat model, “the GPU is a managed accelerator and not an attack surface” is no longer a defensible position.
The State of the Art — And Why It Wasn’t Deployable
The paper opens with a side-by-side comparison of the existing GPU memory-safety designs. The summary is a useful piece of reference material on its own:
| Name | Base | Tag | Tag Size | Metadata | Spatial | Temporal | Deployability | Perf. Overhead1 | Mem. Overhead |
|---|---|---|---|---|---|---|---|---|---|
| GPUShield [33] | HW | ✗ | / | Out-of-band | ● | ○ | ✗ | <1% | None |
| IMT [53] | HW | ✓ | 9/15 | None2 | ● | ○ | ✗ | None2 | 32 B-fragmentation |
| LMI [34] | HW | ✓ | 5 | None3 | ● | ○ | ✗ | <1% | 2n-fragmentation |
| GPUArmor [60] | HW | ✓ | 7/16 | Out-of-band | ● | ● | ✗ | <5% | 16 B/buf |
| GMOD [14] | SW | ✗ | / | Canary | ◐ | ○ | ✓ | <5% | 12 B/buf |
| clArmor [17] | SW | ✗ | / | Canary | ◐ | ○ | ✓ | <10% | 4 B/buf |
| compute-sanitizer [43] | SW | ✗ | / | Out-of-band | ● | ◐ | ✓ | 1,400% | Unknown |
| cuCatch [54] | SW | ✓ | 4–8 | Out-of-band | ● | ◐ | ✗ | <20% | 160 M + 12.5% |
| CuSafe | SW | ✓ | 6* | In-band | ● | ● | ✓ | 13% | 16.5 M + 8 B/buf |
Footnotes from the original:
- Due to the lack of released implementations, the overheads (except for compute-sanitizer and CuSafe) are taken from published papers and are for reference only.
- IMT integrates its checks into ECC and introduces no additional overhead.
- IMT and LMI allocate memory in aligned granules and embed the corresponding tags in pointers, thereby requiring no extra metadata.
* CuSafe might use up to 43 bits for metadata; 37 of them are for VA randomization (see Sec. 4.3) and 6 are for alignment tagging (see Sec. 4.2).
Read down the “Deployability” column. Every hardware-tagging design (GPUShield, IMT, LMI, GPUArmor) needs silicon changes that don’t exist on shipping NVIDIA parts. cuCatch is a software design but is implemented on top of NVIDIA’s proprietary toolchain, which is not released. compute-sanitizer is deployable but lives in a different performance regime (14× on average). GMOD and clArmor are canary-based and inherit canaries’ weakness: an attacker can skip the canary entirely. That leaves CuSafe as the only design that is both software-only on stock NVIDIA hardware and delivers full spatial + temporal coverage.
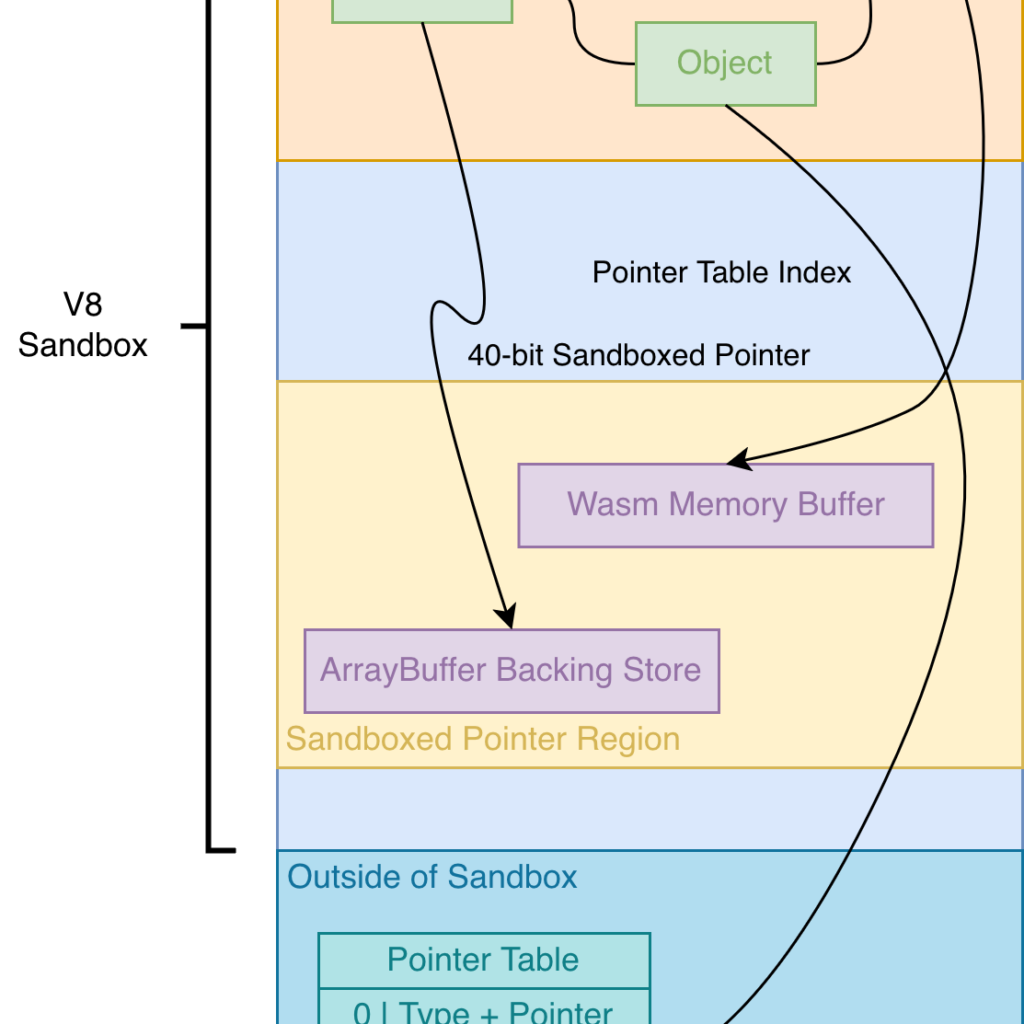
The GPU Memory Hierarchy in 30 Seconds
To understand how CuSafe stores metadata, you need a working picture of the GPU memory hierarchy. The paper’s Figure 1 lays it out: each Streaming Multiprocessor (SM) has private compute units (register file, cores, L1/L2 TLB), a private L1 cache, and shared memory; the chip has a shared L2 cache, a shared L3 TLB, and off-chip device memory partitioned into pageable global memory and per-thread local memory. The relevant facts for sanitizer design:
- Shared memory is a small on-chip scratchpad (~64 KB per SM on current parts), ~100× faster than off-chip DRAM. It overlaps with the L1 cache and the ratio is configurable on some parts.
- Local memory is per-thread off-chip memory used for stacks. NVIDIA’s closed-source driver manages its allocation implicitly — userland can’t control its layout.
- Global memory is also off-chip but is shared across kernels and explicitly managed via
cudaMallocandcudaFreefrom the CPU side. - The MMU walks a hierarchy of page-directory tables (PDx). On Blackwell, PD5 has 256 entries indexed by VA[56], stores PD4 base addresses. PD4–PD1 each have 512 entries indexed by nine bits of VA. PD0 differs: 256 entries indexed by VA[28:21], each entry is either one 16-byte entry storing a 2 MB page frame address, or two 8-byte entries where the lower half points to a 64 KB page frame and the upper half points to a 4 KB page frame.
That MMU design is the key. Because the translation from VA to physical page is solely determined by the contents and structure of these PDx tables, CuSafe can manipulate specific bits in a VA — the bits that would normally be irrelevant noise on top of the physical address — and use them as a tag field, while still mapping to the intended physical page.
Design of CuSafe
Overview
The system has two main pieces, illustrated in Figure 3: a custom memory allocator that hands back tagged pointers to in-band-metadata-prepended buffers, and a compiler-based instrumentation pass that inserts validation checks before every memory access in the GPU code, plus update operations when metadata needs to be rewritten. Allocate → tag → dereference → check is the steady-state cycle.
The metadata itself attaches to two different entities — pointers and buffers — with different fields on each side:
- On the pointer side: the 2n-aligned size (so the system can validate that arithmetic on the pointer hasn’t bumped it past its “belongs to a different buffer” boundary), the pointer’s type bit (global vs. local), and an identity bit (stack epoch for local pointers, randomized VA bits for global pointers).
- On the buffer side: the exact bounds and a liveness flag, embedded in-band at the start of the buffer.
| Entity | Properties | Metadata |
|---|---|---|
| Pointer | Validity (no overflow) | 2n-aligned size |
| Type (global/local) | Pointer type bit | |
| Identity (bind ptr. to buf.) | Stack epoch (local) / Randomized VA (global) | |
| Buffer | Bound & liveness | In-band exact bounds |
Why in-band metadata? GPU workloads are massively parallel: when many threads in a warp access different parts of the same buffer (the parallel for-loop pattern), the hardware can broadcast a single in-band metadata read to all of them in one memory transaction. Out-of-band (shadow) metadata, by contrast, requires each thread to fetch its own different shadow address — the broadcast doesn’t work, you get N transactions instead of 1, and the memory subsystem chokes on the extra pressure. This is the same insight that motivates RSan on the CPU side, applied to the GPU’s very different memory-access broadcast mechanism.
Spatial Corruption Detection
Alignment tagging. CuSafe stores alignment information in pointer bits [46:41] for global pointers and [53:48] for local pointers. The split is a consequence of how NVIDIA’s CUDA runtime treats VA bits. Global pointers always have their [63:47] bits fixed to zero by the runtime, so those bits cannot hold alignment metadata. Bits [46:0] are managed by NVIDIA’s runtime, except the lower bits can optionally be zero’d via the align n attribute — which is what CuSafe uses (bits [53:48] only for local). To distinguish local from global pointers, CuSafe sets bit 47 of local pointers to one (it’s fixed to zero for global pointers). Six bits is enough alignment range: tag value 1 means the minimal 16-byte alignment, so the encoded buffer sizes range from 16 bytes (tag = 1) to 266 bytes (tag = 63). The upper bits [63:54] are reserved to hold an identity tag that prevents metadata confusion after a free / reallocate (more on this below).
In-band exact bounds. The pointer tag only encodes the 2n-aligned size, which is the wrong number for accurate bound checking — a 20-byte buffer pads up to 32 bytes, and a 12-byte out-of-bound write inside that padding would slip past. The exact bound is therefore stored in-band: when CuSafe allocates a buffer of 20 bytes, it prepends 8 bytes of metadata holding the exact size, then aligns the VA to the nearest 2n boundary. The retrieval logic clears the low n bits of the pointer based on the tag and reads the in-band size. The exact bound serves two purposes — it validates that the access is within the buffer’s real (not 2n-aligned) size, and it’s zeroed on free so that any subsequent access through a stale pointer fails the bound check.
Pointer arithmetic validation. The in-band scheme has a gotcha: if pointer arithmetic moves the pointer beyond the 2n-aligned bounds, the retrieval will fetch the wrong metadata (the next allocation’s metadata). The assumption that arithmetic never crosses the 2n-aligned boundary doesn’t hold for real applications — a meaningful tail of PyTorch and TensorFlow bugs originate exactly from pointer miscalculations (integer overflow, off-by-many) that can inadvertently corrupt the tagging bits. CuSafe handles this with a small additional check on every pointer arithmetic operation: take the XOR of the original pointer and the result pointer; if the higher bits (the “modifiable” range outside of 2n+3) are non-zero, the arithmetic has bumped the pointer out of its valid range and the resulting pointer is marked invalid by setting its highest bit. The program is not terminated immediately because some legitimate idioms produce transiently invalid pointers (the final iteration of an array loop); the error is only raised on dereference.
The detection process for spatial violations is then a two-step check on every dereference: (1) is the highest bit set (i.e. did pointer arithmetic invalidate it)? and (2) does the access fall within the in-band exact bound? Both must pass.
Temporal Corruption Detection
Metadata invalidation. Rather than building a separate temporal-safety mechanism, CuSafe reuses the spatial bounds infrastructure. When a buffer is freed, its in-band exact bound is cleared to zero. Any later access through a stale pointer will fail the bound check, because zero is never ≥ access offset. For global buffers (allocated via cudaMalloc / freed via cudaFree), CuSafe instruments cudaFree to do this clearing; for local buffers (which have no explicit free site — they’re cleaned up implicitly on function exit) CuSafe invalidates them at function exit instead.
Metadata confusion. Pure invalidation isn’t enough. When stack memory is reused by a new local variable in another function, that new variable can overwrite the metadata bytes from the previously-freed buffer — making the metadata look valid again, but pointing at the wrong thing. The same problem occurs for global memory if a freed buffer’s VA is reclaimed for a new allocation. CuSafe solves this with two distinct mechanisms: stack epoch tracking for local memory and VA randomization for global memory.
Stack epoch tracking. CuSafe embeds a stack epoch into each local pointer. An epoch is a (stack depth: 5 bits) + (generation: 5 bits) pair. Stack depth is the current thread’s call depth at the time the pointer was created; generation is a per-stack-depth counter that increments every time that depth’s frame is replaced by a newer function call. A local pointer is allowed to dereference only if (1) its stack depth is <= the current thread’s stack depth, and (2) its generation equals the current value at that stack depth.
The implementation involves two global arrays sized at threads/SM × #SMs (for current NVIDIA GPUs, 2048 threads/SM × 132 SMs = 524 288 elements per array, more than enough). The depth array is one byte per element; the generation array is 32 bytes per element (one byte per possible stack depth value 0–31). Total: ~16.5 MiB. The stack-epoch validation logic on each local dereference looks like the listing below:
void func() {
f_d=*_d[tid]; f_g=*_g[f_d];
int buf[10];
assign_epoch(buf, f_d, f_g);
int *ptr = local();
if(f_d > ptr_d || f_g != ptr_g)
report_violation();
_d[tid]--;
}The function fetches the current stack depth f_d and the generation f_g at that depth, assigns the new epoch to the local buffer buf, and dereferences ptr which was returned by a previously-called local(). If ptr’s recorded stack depth exceeds the current f_d (meaning the frame that allocated it has been popped), or its generation differs from the current generation at that depth (meaning the same depth has been refreshed by a different function), CuSafe reports the violation.
The 5-bit depth and 5-bit generation cap out at 32. The paper’s experiments show CUDA functions in practice reach a maximum stack depth of 17, so 32 is fine. The generation does have a corner case: an obsolete pointer is dereferenced after exactly 32 same-depth function calls, which would cause the generation to wrap. The paper considers this scenario rare and notes that future hardware could push the depth to 0 and fall back to a probabilistic defence with P(collision) = 1/32.
VA randomization. For global memory, CuSafe randomizes bits [40:A] of every global pointer, where A is the buffer’s alignment exponent. For a 16-byte buffer A=4, so 37 bits are randomized — 237 possible VAs per allocation, making the probability of collision with a previously-freed buffer effectively zero. Even in the worst case (8 GiB allocations, A=33), the address space still provides 28 = 256 random slots, and a typical 80 GiB GPU can hold at most 10 such allocations before running out of memory. For practical 1 MiB allocations (A=20), the random space is 221. The current design is constrained by NVIDIA’s fixing of bits [63:47] to zero; if that restriction were lifted, the random space could grow much further. Compare to cuCatch’s fixed 256-slot space (8 random bits) regardless of allocation size, which leaves it materially exposed to metadata confusion when many concurrent allocations exist.
Optimization — Removing Redundant Checks
A naive instrumentation pass would emit a separate validation on every pointer dereference, including many that are logically implied by an earlier validation in the same basic block. CuSafe deploys three LLVM optimizations to remove the redundant work:
Recurring checks. The same pointer is dereferenced repeatedly inside a branch. The dominating check guarantees the validity of every subordinate one; the subordinates can be elided:
__global__ void ker() {
__shared__ int A[10];
int tid = threadIdx.x;
_check(A, tid); // Cdom
if (tid % 32 > 28) {
_check(A, tid); // Csub
}
}Neighboring checks. Multiple checks on the same base address with different offsets, all in the same basic block. Only the maximum and minimum offsets need to be checked — all intermediate offsets are implied:
__global__ void ker(int* A, int N) {
int l = tIdx.x, s = bDim.x;
for (int i=1;i<N;i+=s) {
_check(A, i+2); // Cmax
// _check(A, i+1);
_check(A, i+0); // Cmin
}
}Loop-inductive checks. If the offset in a check is a loop-inductive variable (one that changes by a constant amount per iteration), the maximum and minimum values across all iterations can be pre-computed at the loop prologue, hoisting the check out of the loop body entirely. The example below: a loop runs i from 0 to N-1 with stride s; the check for A[i] is replaced by a single check at the prologue covering offset 0 (min) and N-1 (max). Loop-invariant checks (offset is a constant inside the loop) are a special case of the same transformation:
__global__ void ker(int* A, int N) {
int l=tIdx.x, s=bDim.x;
_check(A, 0); // Cmin
_check(A, N - 1); // Cmax
for (int i=1;i<N;i+=s) {
_check(A, i);
}
}Across the 44-program benchmark suite, these three optimizations eliminate an average of 19.32% of checks (the “Average %” line in the paper’s Figure 16). The most extreme single benchmark is lud, where the optimizations reduce execution time by over 60% by enabling the compiler to coalesce shared-memory accesses that the redundant checks had been pessimising.
Implementation and Deployment
CuSafe is implemented as an LLVM 21 transform pass plus a dynamic library hooking the CUDA APIs. Total size: 2 964 lines of C/C++. The CUDA build pipeline is modified at two points: the LLVM frontend pass runs -On with the CuSafe pass appended, producing an instrumented LLVM IR (.ll / .ptx). NVIDIA’s proprietary nvcc backend then turns this into an executable. At runtime, CuSafe’s dynamic library is preloaded via LD_PRELOAD and replaces cudaMalloc (and the other allocation APIs) so that allocated memory carries the in-band metadata bytes.
This split is the engineering trick that makes CuSafe deployable on commodity NVIDIA hardware without source access to NVIDIA’s tooling. Everything CuSafe needs is at the LLVM IR level (before nvcc) and at the userland API level (after nvcc) — the proprietary backend is left untouched.
Evaluation Results
Security coverage
The authors built a benchmark of 33 GPU programs with known bug patterns: 15 spatial corruption tests (9 linear, 6 non-linear) and 18 temporal corruption tests (12 use-after-free, 2 invalid-free, 4 double-free). The detection results across the comparison set:
| Type | # | compute sanitizer | GPU Shield1 | cuCatch1 | LMI1 | CuSafe | |
|---|---|---|---|---|---|---|---|
| Spatial | Linear | 9 | 3 | 3 | 6 | 3 | 9 |
| Non-linear | 6 | 0 | 5 | 4 | 3 | 6 | |
| Coverage | 20% | 53.3% | 66.7% | 60% | 100% | ||
| Temporal | UAF | 12 | 4 | N.A.2 | 9 | 6 | 12 |
| IF | 2 | 2 | N.A. | 1 | 0 | 2 | |
| DF | 4 | 4 | N.A. | 4 | 4 | 4 | |
| Coverage | 55.6% | / | 83.3% | 66.7% | 100% | ||
The headline result: CuSafe is the only system in the comparison that scores 100% on both spatial and temporal coverage. compute-sanitizer catches the spatial cases extremely poorly (3 of 15) because it relies on the 2n-aligned size for bound checking — missing every non-linear overflow and most linear ones — and only catches 10 of 18 temporal cases. cuCatch does well on temporal coverage (83.3%) but tag collisions with 8-bit tags become likely as the live buffer count exceeds 256. LMI’s metadata invalidation embeds its data only in the pointer, so any copy of the pointer made before the free escapes invalidation; that misses every UAF where the dangling reference is a copy.
Runtime overhead
The 44-program performance benchmark mixes well-known GPU benchmark suites with LLM inference:
| Suite | # | Testcases |
|---|---|---|
| Rodinia | 17 | b+tree, bfs, backprop, lavaMD, bfs, gaussian, pathfinder, srad, particlefilter, lud, nn, particle_naive, particle_float, sradv1, sradv2,hotspot, hotspot3d, dwt2d, heartwall, needle, pathfinder |
| PolyBench | 19 | conv2d, conv3d, adi, fdcg, covar, gramschmidt, jacobi1d, jacobi2d, fdtd, genver, mvt, 2mm, 3mm, atax, corr, doitgen, gemm, gesummv, lu |
| Tango | 6 | AlexNet, CifarNet, GRU, LSTM, ResNet, SqueezeNet |
| LLM | 2 | LLaMA2, LLaMA3 |
The hardware is an AMD Ryzen 9950X paired with an NVIDIA RTX 5090 (32 GiB), running Linux 6.12.21, NVIDIA driver 570.144, CUDA 12.8. The overhead is measured with cudaEventElapsedTime, excluding host↔device memcpy and initialization. The headlines:
- Average runtime overhead: 13%. compute-sanitizer’s comparable number on the same benchmarks is 15× (1 500%) on average, with worst-case 153×.
- Worst case for CuSafe: 83%, observed on
gemmin PolyBench — a naive matrix multiplication implementation with sparse memory access that hurts cache efficiency. The same workload on compute-sanitizer is 153×. - LLM throughput: ~11% drop on LLaMA2-7B and LLaMA3-8B; the same workload on compute-sanitizer drops throughput by 98.5%.
- For comparison, the related (but undeployable) cuCatch reports 19% average overhead with a 3.1× maximum.
Memory overhead
The paper analyses memory overhead in two ways. The first decomposes each tool’s overhead into fixed and scalable components:
| Tool | Memory overhead |
|---|---|
| LMI | 2n-aligned fragmentation |
| cuCatch | Fixed part: 160 MiB; Scale part: 12.5% |
| CuSafe | Fixed part: 16.5 MiB; Scale part: 8 bytes/alloc |
The fixed cost (16.5 MiB) is the stack-epoch arrays. The scalable cost (8 bytes per allocation) is the in-band exact-size metadata. CuSafe doesn’t need to allocate physical memory to fill 2n-aligned padding regions; the alignment is enforced only on VAs, with the physical mapping covering only the actually-used portion.
The empirical measurement on real workloads:
| cuCatch | LMI | CuSafe | ||
|---|---|---|---|---|
| Relative | Max | 160 MB (5121.5×) | 32 MB (2×) | 16.5 MB (528×) |
| jacobi1d | needle | jacobi1d | ||
| Absolute | Max | 3.79 GB (13%) | 6.89 GB (23.7%) | 16.51 MB (0%) |
| llama2 | llama2 | llama3 | ||
| Average | 0.73 GB (15%) | 1.10 GB (23%) | 0.5 MB (0.01%) | |
For LLM inference the difference is consequential: cuCatch adds 3.79 GB of memory overhead on LLaMA2, LMI adds 6.89 GB — either can push the inference out of GPU memory on commodity parts. CuSafe’s 16.5 MiB is irrelevant by comparison. That property is precisely what makes the design viable for the LLM use case the paper specifically calls out.
GPU-specific metrics: occupancy and divergence
Two GPU-specific metrics matter beyond raw overhead. Occupancy is the fraction of active warps per SM — low occupancy means the GPU is under-utilised. Across 113 instrumented CUDA kernels, only 13 showed an occupancy drop of more than 10%, six of which involve matrix multiplication (gemm). The largest drop (50%) was on lavaMD from Rodinia. Importantly, occupancy changes do not directly correlate with CuSafe’s runtime overhead — gemm had 83% overhead but only 24% occupancy drop, while lavaMD had <1% overhead but 50% occupancy drop. This indicates that CuSafe’s overhead is dominated by additional instructions, not reduced occupancy.
Divergence occurs when threads in a warp take different branches and the GPU has to serialise execution. CuSafe inserts additional conditional branches in its checks, but they only branch on validity — divergence in those branches means memory corruption is occurring, and the program is expected to terminate. The paper measured divergence rate before and after CuSafe instrumentation and observed no measurable increase.
Discussion — Where CuSafe Doesn’t Help (Yet)
The paper is candid about a few limitations worth flagging for anyone evaluating deployment.
- Intra-object overflow. Bounds are at object granularity — one
struct= one bound. Overflows between two fields in the same struct aren’t caught. Field-level granularity is achievable in theory but would explode the tracked-object count and the runtime cost. - Benign overflow. Programs that legitimately compute a transiently out-of-bound pointer and recover before deref will be flagged false-positive if the increment crosses the buffer’s 2n-aligned boundary by enough. The paper’s Figure 17 example:
p += 700; p -= 700;on a 600 B 1KB-aligned buffer is benign and tolerated.p += 1024;on the same buffer would not be tolerated. The authors regard this as a tail-case rare in practice. - Uninstrumented libraries. CuSafe runs in the LLVM frontend, so closed-source libraries (cuDNN, cuBLAS) can’t be instrumented. CuSafe handles this safely by stripping its metadata before invoking them. Global pointers are MMU-tagged and can be passed safely; local/shared pointers need explicit untagging. Uninstrumented libraries can be detected by their lack of tag bits and validation can be skipped on their returned pointers, avoiding false positives.
- Unsupported memory types. Two paths CuSafe currently doesn’t cover: dynamic shared memory (sized at kernel launch via
<<<dim_grid, dim_blk, size_shared>>>, allocated by NVIDIA’s runtime which CuSafe can’t intercept) and in-kernelmalloc(which has heavy native overhead anyway and is rarely used). Shared memory is capped at ~64 KiB so static allocation is generally sufficient. - Other GPU vendors. The underlying mechanism doesn’t depend on anything NVIDIA-specific — AMD GPUs would be straightforward (HIP is open and structurally similar to CUDA); Intel and Apple GPUs are harder because their low-level memory-management APIs are more restrictive.
- Other compilers / JIT. The current implementation is LLVM-only, which means no JIT compilation support.
Tolerating Benign Overflow — A Worked Example
The paper’s Figure 17 illustrates the false-positive corner case. Consider a 600-byte buffer aligned to 1 KB. A program that bumps p by 700 bytes and then subtracts it back by 700 bytes stays within the 1 KB alignment boundary and is therefore tolerated — CuSafe sees no metadata alteration:
//600B; 1KB-aligned;
char p[600];
//+700 not invalidated(<1024)
p += 700;
p -= 700; //recoveredIf the increment had been 1024 instead, the XOR would show changed bits in the 2n-aligned region, the pointer would be invalidated, and the subsequent recovery would not undo the invalidation — CuSafe would raise a (false) alarm at the next dereference. The paper considers this rare enough not to materially impair deployability.
Comparison with RSan (CPU side)
For readers familiar with CPU-side memory safety, the in-band metadata idea will look like RSan (USENIX Security ’25). The conceptual overlap is real but the design pressures are different. RSan’s in-band scheme reduces metadata-retrieval overhead by collapsing checks into a single memory access; CuSafe’s use of in-band data is motivated specifically by GPUs’ memory access broadcast mechanism that out-of-band shadow memory cannot exploit. Both validate pointer arithmetic to protect their own metadata, but RSan omits that part because mature CPU compilers (UBSan, etc.) already catch the relevant integer overflows at compile time. On the temporal side, RSan focuses on spatial errors only; CuSafe extends to temporal errors through metadata invalidation, stack epoch tracking and VA randomization — because GPU return addresses live on the stack (per Guo et al.’s USENIX ’24 finding) and are vulnerable to ROP if temporal safety is left to user code.
Key Takeaways
- The first software-only, deployable GPU sanitizer with 100% spatial + temporal coverage. Every other entry in the paper’s comparison table is either non-deployable on stock NVIDIA hardware (hardware-modification designs, cuCatch’s proprietary-toolchain dependency) or has materially incomplete coverage (compute-sanitizer at 20% spatial, GMOD/clArmor canaries).
- 13% average runtime overhead is the deployability threshold being crossed. compute-sanitizer’s 15× (1 500%) is fundamentally a debug-time-only tool; CuSafe at 13% is in production-deployment range, especially for security-sensitive ML pipelines that today run with no GPU memory safety at all.
- 16.5 MiB total memory overhead matters for LLM serving. cuCatch’s 3.79 GB on LLaMA2 and LMI’s 6.89 GB are both potentially fatal to inference fitting in commodity GPU memory; CuSafe’s overhead is irrelevant to the same workloads.
- The MMU-as-tag-storage trick is the engineering keystone. Manipulating VA bits that the MMU translates back to the intended physical page is what lets CuSafe encode pointer metadata without needing any hardware changes or proprietary-toolchain access.
- Stack-epoch tracking and VA randomization between them defeat metadata confusion. 5-bit depth + 5-bit generation cover real-world CUDA stack depth (max 17 observed); VA randomization with 37 bits makes collision probability negligible. cuCatch’s 8-bit tag has known collision problems beyond 256 live buffers; CuSafe’s scheme doesn’t.
- Three optimization passes eliminate ~20% of checks on average, and on memory-bound workloads like
ludthe secondary effect of letting the compiler coalesce shared-memory accesses reduces execution time by >60%. - The artefact is public. CuSafe’s LLVM pass, dynamic library, and benchmark suite are released on figshare, and the paper carries the USENIX Artifact Evaluated / Available badge — meaning the security community can use it today, not in some indeterminate future.
Defensive Recommendations
- Run GPU memory safety in CI for ML pipelines. Anyone shipping CUDA-based ML inference or training should now bake a sanitizer pass into pre-merge CI for any PR touching CUDA kernels. CuSafe’s 13% overhead and tiny memory footprint make this feasible against LLaMA-scale workloads without renting more GPUs.
- Stop relying on compute-sanitizer as a debug-only tool. compute-sanitizer’s 20%/55% spatial/temporal coverage means a lot of real bugs slip past it. Even at debug time, supplement it with CuSafe to surface non-linear overflows and the UAF cases compute-sanitizer misses.
- Audit GPU code for the bug classes already in the wild. The PyTorch issues the paper cites (#144611, #145349, #154724) and the TensorFlow issue (#94118) point to specific bug-class patterns — integer overflow into pointer arithmetic, off-by-many in convolution implementations, sparse buffer index miscalculation. Sweep your own kernels for the same patterns.
- Treat the GPU as an attack surface, not a managed accelerator. Guo et al.’s USENIX ’24 work demonstrated ROP on the GPU; Park et al. demonstrated model-prediction subversion; Roels et al.’s 2025 work showed canary-based defenses are weaker on GPUs than CPUs. ML inference services, in particular, should reason about GPU-resident attacker capabilities the way they reason about CPU-resident ones.
- For multi-tenant GPU services, plan for memory-isolation telemetry beyond hardware enforcement. Until GPU vendors ship MMU/MTE-style hardware tagging widely, software sanitizers like CuSafe will be the only thing standing between tenant workloads in shared GPU contexts. Build in observability hooks (violation reports, exit codes) and route them into the same incident pipeline as CPU-side address-space corruption.
- Track the GPU sanitizer space. CuSafe is a USENIX Security ’26 paper, which means the next two years will probably bring follow-up work tightening the corner cases (intra-object granularity, dynamic shared memory, JIT, non-NVIDIA vendors). The artifact being released early gives the community time to evaluate, harden, and integrate before broader adoption pressure hits.
- Tighten allocation hygiene in GPU code now. Many of the bug classes CuSafe catches are addressable at source: bounds-check arithmetic that derives pointer offsets from untrusted inputs, separate types for buffer-relative offsets vs. absolute pointers, no
cudaMallocsizes derived without overflow-checked multiplication. Doing this work pre-emptively reduces the number of CuSafe-triggered fires in production. - Don’t wait on closed-source library coverage. cuDNN / cuBLAS / cuFFT and the rest of NVIDIA’s proprietary stack remain uninstrumented under CuSafe (and any LLVM-based approach). Your code — the kernels you actually wrote — is the surface you control. Get CuSafe on those first, then push NVIDIA and the open-source alternatives (MAGMA, ArrayFire) for sanitizer-friendly distributions.
Conclusion
CuSafe matters because it converts “GPU memory safety is theoretically interesting but practically undeployable” into “there is now a usable sanitizer that runs at 13% overhead on commodity NVIDIA hardware and the source is on figshare.” The design’s cleverness — using the MMU’s page directory translation to encode pointer metadata, combining 6-bit alignment tagging with in-band exact bounds, defeating metadata confusion with stack epochs and 37-bit VA randomization, eliminating ~20% of redundant checks via three LLVM optimizations — is what gets you to that overhead number. But the real significance is that the GPU has finally caught up to the CPU on memory-safety tooling at the deployability frontier. The next stop is integrating this kind of pass into production ML build systems so that a non-trivial fraction of the GPU-side bug pipeline gets cut off before reaching users.
Original text: “CuSafe: Capturing Memory Corruption on NVIDIA GPUs” by Hongyi Lu, Fengwei Zhang, Zhenkai Zhang, Shuai Wang, Yanan Guo at USENIX Security ’26 (pre-publication). Source code: https://doi.org/10.6084/m9.figshare.30821396.