

Executive Summary
Andy Gill of ZephrSec spent the early part of 2026 wiring Claude Code into an isolated Proxmox lab via eight Model Context Protocol (MCP) servers exposing roughly 300 tools, then pointed the orchestrator at real targets. The result is a self-improving vulnerability hunting pipeline that has already produced two assigned Go standard-library CVEs (CVE-2026-33809 in x/image/tiff, CVE-2026-33812 in x/image/font/sfnt), a four-stage OEM update-service chain ending in SYSTEM code execution on Windows 11 25H2, and two further findings in a macOS application distributor — with multiple Windows LPEs, RCEs and use-after-frees in the pipeline.
The article walks through the architecture in detail: a hallucination bin that treats every finding as guilty until proven innocent across four validation gates, a FAISS-backed RAG knowledge loop that compounds across campaigns, a bounty-intelligence module that ranks targets by expected ROI, and TokenBurn — a self-hosted dashboard for measuring whether a Claude Max subscription actually beats API billing for spiky security research workloads. The honest review is more interesting than the headline: most campaigns find nothing, the hallucination bin is much larger than the findings directory, and the economics only work because every failed campaign still feeds the knowledge base.
Andy spent a week off the day-job writing up the “0day machine” he has been quietly tinkering on since early 2026 — an autonomous vulnerability hunting system glued together with Claude Code and the Model Context Protocol. A friend’s verdict, lifted from a private group:
Andy basically is slave labouring the AI
Private group chat
The title itself is a nod to GenAI = Jenny and the song “Jenny Was A Friend Of Mine” by The Killers, embedded in the original post.
Using LLMs for security research is nothing new, and neither is custom tooling that automates the boring parts of fuzzing — Stephen Sims was doing fuzzing at scale in 2014. What is new is the combination of Claude Code, MCP, and a purpose-built isolated lab. Andy built TokenBurn explicitly to answer the “is Claude Max + this hardware actually worth it?” question with data:
The original motivation was painfully familiar: more time spent wrangling tooling than actually hunting bugs — SSH to a VM, stage a binary, decompile it, map attack surface, set up fuzzing, triage crashes, write a PoC, draft a disclosure. Each step has its own tools, formats, and context to carry across the seam. Andy wanted Claude to handle the wrangling while he kept the thinking and the writing — partly because, in his words, AI does not write like humans and partly to preserve technical ownership of the research.
A Quick Rundown on MCPs
The Model Context Protocol exposes tools to Claude Code as callable functions — typed inputs, typed outputs, no copy-pasting terminal output between windows. Each MCP server is essentially a Python process that registers tools, and Claude calls them directly during a conversation.
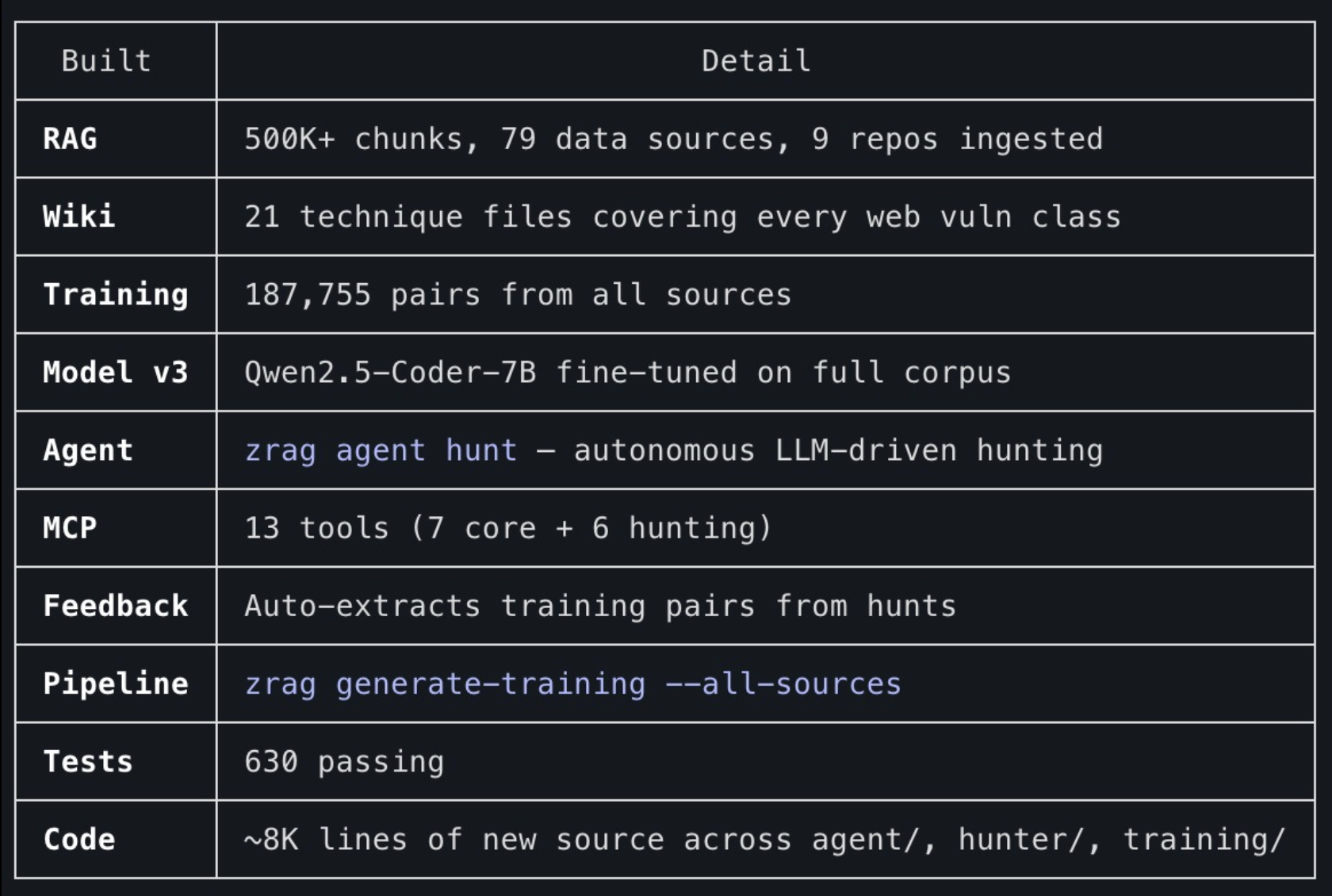
The recipe here is to wrap every research-workflow tool as an MCP server. The lab ended up with eight MCP servers spread across five VMs, exposing over 300 tools. A high-level breakdown:
| Server | Purpose |
|---|---|
| Lab Controller | SSH/WinRM sessions, Proxmox VM management, basic RE |
| Hunter | Patch diffing, attack surface enumeration, 10 fuzzing domains, crash triage, campaigns |
| RE Tools | Ghidra, radare2, Frida and some other tools |
| Exploit Dev | Shellcode generation, heap spray, CFG bypass, PoC assembly, emulation |
| Debugger | Persistent WinDbg/GDB sessions that survive across tool calls |
| RAG | Semantic search across all campaign data, findings, and prior research |
| Infra | Provision and scale fuzzing VMs on Proxmox |
| Reporting | Disclosure reports, bounty submissions, CVE requests |
The coloured dots next to each VM indicate which category each MCP falls under and which VM it is assigned to, making it easy to recognise responsibilities at a glance.
All eight processes run under Claude Code, registered in a single .mcp.json. When Claude needs to enumerate loaded Windows drivers it calls tool_surface_kernel_drivers; for a decompilation, tool_re_ghidra_decompile; to kick off a fuzzing campaign, the per-domain tool_*_fuzz_start.
Each server is built with FastMCP. The server files are thin @mcp.tool() wrappers; the business logic lives in dedicated subdirectories (hunter/, re_tools/, exploit_tools/, debug_tools/). SSH and WinRM sessions persist across tools within a conversation and across sub-agents — you connect once, and the rest of the chain just works.
The Lab
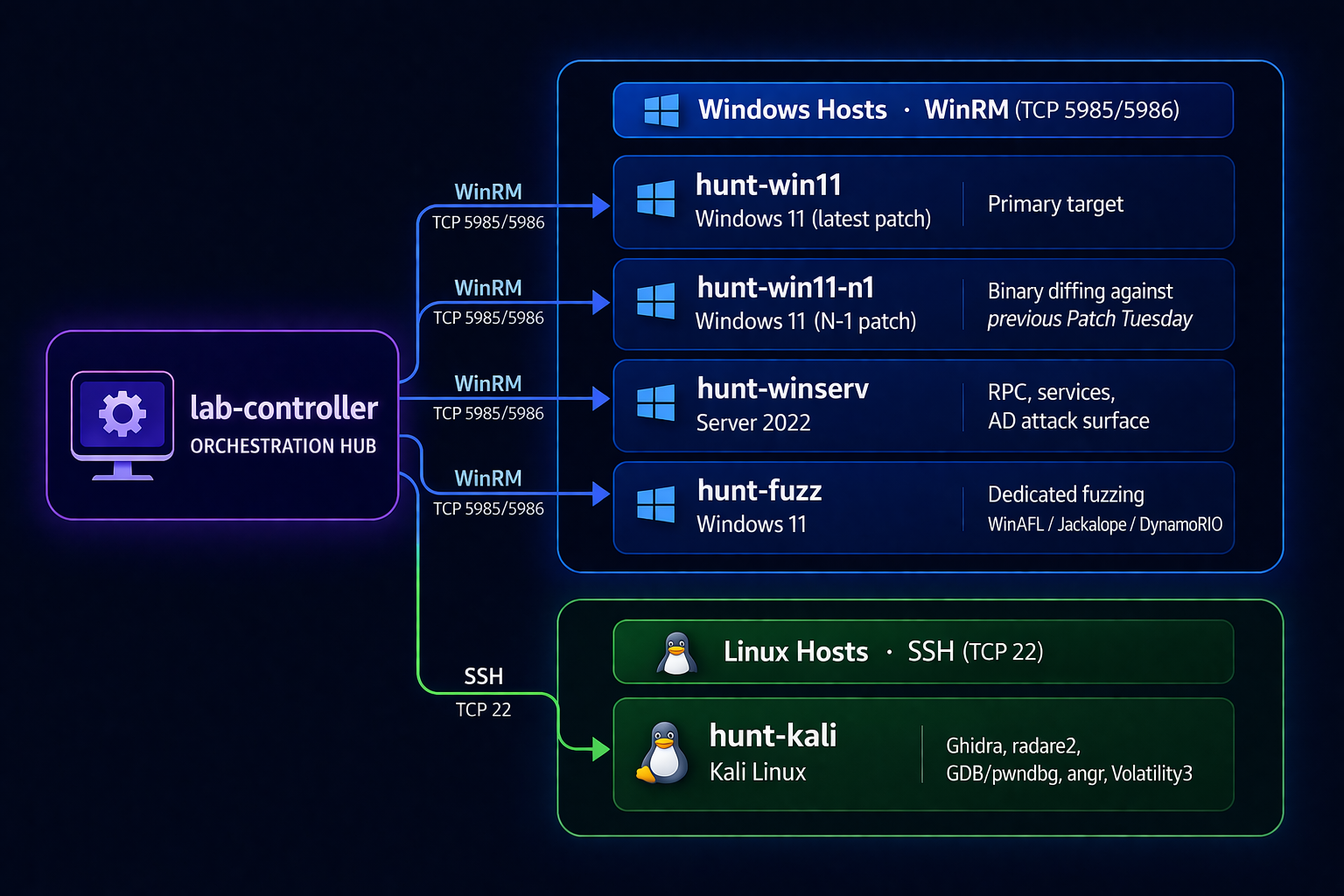
Research runs on a Proxmox-based hunt range with five VMs on an isolated network segment. Andy is in the middle of rewriting his home-lab series; the host below replaces the existing NUC-based setup from the prior series at blog.zsec.uk/homelab-clustering-pt1.
Nothing exotic in the layout — just purpose-built for the workflow:
| VM | Platform | Role |
|---|---|---|
| hunt-win11 | Windows 11 (latest patch) | Primary target |
| hunt-win11-n1 | Windows 11 (N-1 patch) | Binary diffing against previous Patch Tuesday |
| hunt-winserv | Server 2022 | RPC, services, AD attack surface |
| hunt-kali | Kali Linux | Ghidra, radare2, GDB/pwndbg, angr, Volatility3 |
| hunt-fuzz | Windows 11 | Dedicated fuzzing (WinAFL, Jackalope, DynamoRIO) |
Each Windows VM has a lowpriv standard user account. This matters more than it might look: early on, a number of findings that looked great from SYSTEM turned out to be completely unreachable as a normal user, which is why Gate 3 of the validation pipeline below exists.
Windows binaries are staged to hunt-kali over SFTP (tool_re_stage) so radare2 and Ghidra never need to run on the targets themselves. The two Windows 11 VMs (latest and N-1) drive binary diffing across Patch Tuesdays — enumerate what changed, diff the binaries, and identify security-relevant fixes worth targeting in dedicated campaigns. There is also a Patch-Tuesday-tuned MCP that focuses specifically on patch diffing.
Campaigns and the Hallucination Bin
LLMs hallucinate. They will confidently invent a control-flow path, a function name, or a vulnerability that does not exist. The system treats this as a primary engineering constraint, not a footnote.
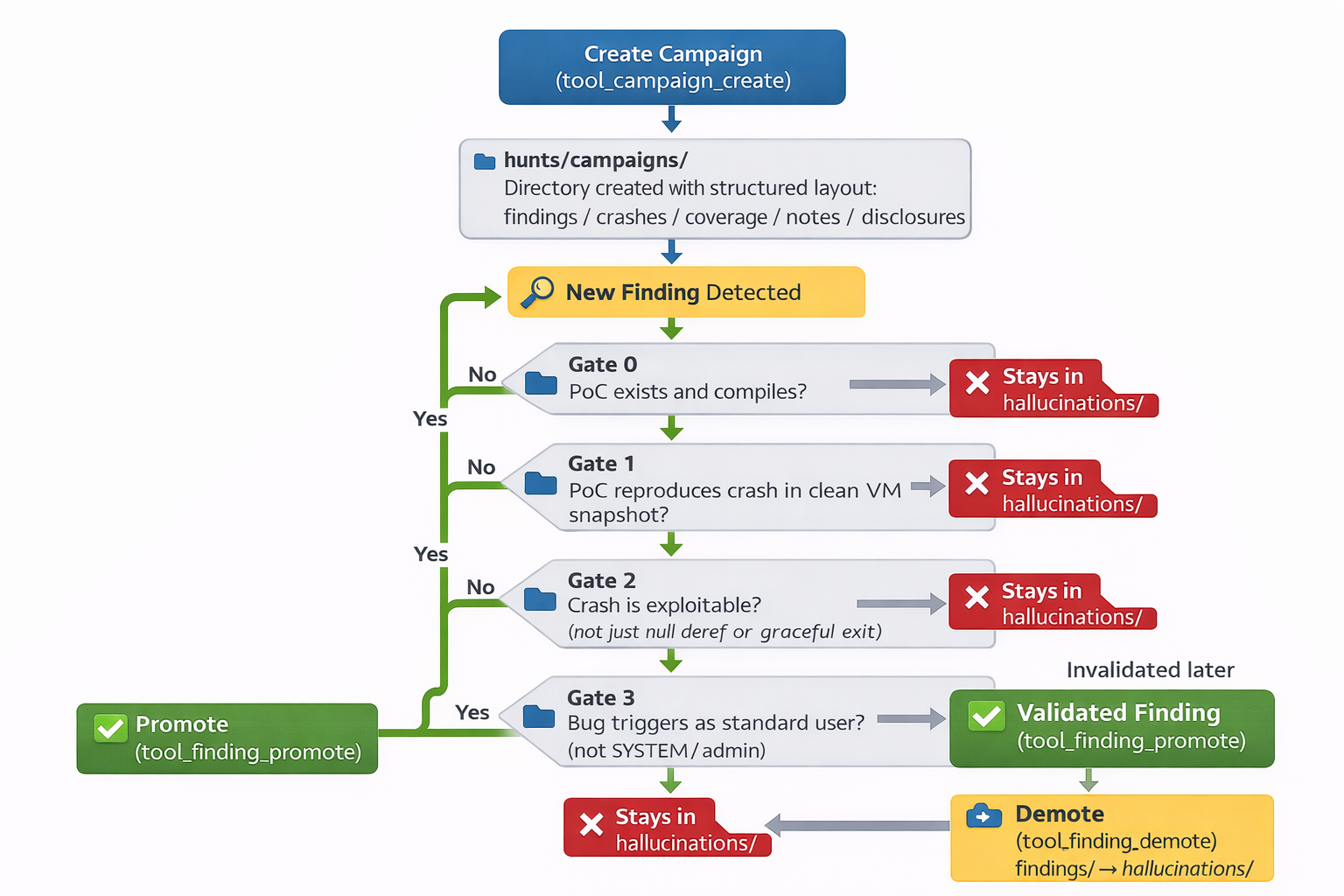
Hunting work is organised into campaigns. A campaign is a directory under hunts/campaigns/ with a structured layout for findings, crashes, coverage data, notes and disclosures. Create one with tool_campaign_create; everything else attaches to it.
The single most important design decision in the whole system is the one Andy says he should have made on day one: findings start as hallucinations. Every new finding goes into hallucinations/, not findings/. Promotion to a real finding requires passing four validation gates:
- Gate 0: PoC exists and compiles
- Gate 1: PoC reproduces the crash in a clean VM snapshot
- Gate 2: Crash is exploitable (not just a null deref or a graceful exit)
- Gate 3: Bug triggers as a standard user, not SYSTEM or admin
It sounds paranoid — it should sound paranoid. The system needs enough self-awareness to recognise its own confident-sounding nonsense. Andy notes the human sits in the loop too, so vendors never get flooded with garbage reports.
One early session illustrates the pattern: the autonomous engine surfaced six findings that looked promising in logs and decompilation; under manual review and dynamic analysis, all six fell over. The hallucination bin caught every one before they got near a vendor.
The promotion flow is tool_finding_promote (moves hallucinations/ → findings/) and tool_finding_demote (the reverse, when something gets invalidated later). Simple, but it enforces the discipline that nothing leaves the pipeline without proof.
The Knowledge Loop
Every fuzzing-start tool queries the local RAG index for prior findings before launching. Every crash and finding records its outcome after. The result is a continuous feedback loop where the system literally gets smarter with each hunt.
The loop runs in five stages:
- Hunt — before a campaign, query the knowledge base: have crashes been seen in this binary or this application class before? What techniques worked? What defences blocked them?
- Collect — every crash across all 10 fuzzing domains is recorded with domain, target and crash class
- Enrich — vendor advisories, patch diffs, variant analysis matches, bounty submissions and coverage-plateau events all feed in
- Learn — everything auto-indexes into a FAISS vector store with sentence-transformer embeddings
- Repeat — the next hunt starts with richer context
If ntoskrnl.exe produces a crash pattern in one campaign, the next campaign that touches ntoskrnl.exe already knows about it. Recurring vulnerability classes across campaigns surface automatically by semantic similarity, and dedup happens with no manual effort.
A separate known-defence database catches the opposite case. When a target is found to be hardened — AM-PPL (Antimalware Protected Process Light), Side-by-Side protection, strict Authenticode validation — the defence is recorded and multiplicatively reduces that target’s priority score on future hunts. After the first few campaigns kept walking into AM-PPL walls, the system stopped recommending those targets entirely.
Alongside the lab’s RAG, Andy maintains a separate local RAG indexing 561,000+ chunks of his own notes built up over a decade and a half, 5,800+ public Sigma rules, 1,025 curated GitHub repos, tool docs — the lot. It runs locally via Ollama and is itself an MCP server, so Claude can query the entire offensive-security knowledge base inline. The result is that techniques come back as Andy’s own methodology with his exact commands, not generic summaries from training data.
Bounty Intelligence
A second MCP tracks 100+ bug bounty programmes across various platforms with ROI scoring across vulnerability classes (RCE, LPE, auth-bypass, type confusion, UAF, heap overflow). Before committing time to a target, it estimates the expected payout based on:
- The target binary’s patch history (frequently patched = more attack surface being found = more to find)
- Vulnerability class and severity tier
- Programme payout ranges and historical acceptance rates plus triager knowledge based on types of findings coming out of programs
- Known defence mechanisms present on the target
That feeds into target ranking the autonomous engine consults when deciding what to fuzz next. It is not perfect — programmes change scope and payouts — but it prevents the classic mistake of grinding for a week on a target that caps at $500 when a $250K hypervisor-escape bounty is sitting right there.
Fruits of Labour
Architecture is nice, but the question is whether it earns its keep. Below are the findings the system has produced so far that are public enough to discuss.
Multiple Go Standard Library CVEs
A fuzzing campaign against Go’s golang.org/x/image package produced two CVEs in two weeks. Both are OOM bugs that crash any Go process handling untrusted input. The vulnerable code sits in the standard library’s extended image packages, so anything that processes user-supplied images or fonts — web servers, chat platforms, CI pipelines — is potentially in scope.
CVE-2026-33809 — x/image/tiff: OOM from Malicious IFD Offset
An 8-byte crafted TIFF file with IFD offset 0xFFFFFFFF causes buffer.fill() to allocate roughly 4 GB of memory when decoding via the io.Reader path (non-ReaderAt), OOM-killing the process.
The payload is literally eight bytes:
\x49\x49\x2a\x00\xff\xff\xff\xff
That is a valid TIFF header (little-endian, magic 0x002A) followed by an IFD offset pointing to the end of the 32-bit address space. When buffer.fill() tries to read up to that offset it allocates a buffer big enough to hold the entire range — about 4 GB of zeroes for an 8-byte file. The allocation slips through because safeReadAt (the fix for CVE-2022-41727) doesn’t cover the IFD-offset read at reader.go:477, which is a distinct code path.
Affected versions: all golang.org/x/image from v0.0.0 through v0.37.0 — every version ever released. The Go module graph shows 945+ downstream packages pulling in the vulnerable code.
The fix: read data and grow buffers in chunks, capping growth to the actual input size rather than trusting the IFD offset. Andy submitted it as golang/image#25, merged as commit 23ae9ed.
Downstream impact: reports filed against multiple downstream consumers (where the real impact lands) and submitted upstream via the vendor’s open-source vulnerability rewards programme.
CVE-2026-33812 — x/image/font/sfnt: OOM via Unchecked GPOS Class Count Product
A crafted font file triggers a multi-gigabyte allocation while parsing GPOS PairPos tables. In parsePairPosFormat2, numClass1 and numClass2 are read as uint16 values straight from the font and their product is passed unchecked to source.view(). With both values at 65,535, the product times 2 reaches roughly 8 GiB — instant OOM.
Only the io.ReaderAt path is affected (the []byte path is bounded by the slice length). During investigation two further issues surfaced in the same code:
makeCachedPairPosGlyphandmakeCachedPairPosClassdon’t validate that indices derived from the font file fall within the parsed buffer before indexingsource.varLenViewdoesn’t check for integer overflow when computing total length
The fix: validate the class-count product against maxTableLength before allocating, add bounds checks on indices in the PairPos kern functions, and add overflow checks in varLenView. Submitted as golang/image#26, merged as commit 854c274.
The Broader Fuzzing Campaign
Both CVEs came out of a broader effort: 21 Go standard-library packages fuzzed across roughly 80 million total executions in 3–30 minute sessions per target. The campaign covered tiff, sfnt, webp, gif, png, jpeg, gob, asn1, x509, pem, ssh, zip, tar, gzip, xml, html, ccitt, tiff/lzw, and others. Only TIFF and SFNT produced confirmed vulnerabilities. WebP and GIF dimension-based allocations were investigated but confirmed as working-as-intended by the Go maintainers.
The grammar-based fuzzing domain was the key piece. Throwing random bytes at image parsers mostly produces “invalid format” errors; the grammar engine instead generates structurally valid files with adversarial field values — a valid TIFF header carrying a malicious IFD offset, a valid OpenType structure carrying extreme class-count values.
OEM Service 0-Day — Auth Bypass + SSRF → SYSTEM Code Execution
The bounty intelligence pipeline flagged a Windows OEM system-management agent as a high-value target: vendor runs a public bounty programme, the software ships on millions of enterprise machines, and it runs a SYSTEM service with a rich WCF interface — third-party OEM software, typically less scrutinised than OS components. The RE tools decompiled the WCF interface, exposing the full service contract. The result was a four-stage chain from standard user to SYSTEM code execution.
1. Named Pipe Authentication Bypass
The update service exposes multiple SYSTEM-level WCF named pipes reachable from any local user. The catch: authentication is implemented entirely client-side. The server does no authentication at all on incoming pipe connections. The bypass uses AppDomainManager injection into the vendor’s own signed service binary.
2. SSRF via WCF
One WCF method takes an attacker-controlled URL parameter with no admin check. Unlike other methods on the interface, this one skips privilege verification entirely. The SYSTEM service dutifully fetches HEAD + GET against whatever URL it is handed, with a vendor-specific user-agent string. Confirmed via HTTP logs showing SYSTEM-context requests to an attacker-controlled endpoint.
3. Catalog Injection
The attacker’s crafted update-package descriptor is accepted and returned as an applicable update. The data contract uses a vendor-specific serialisation format. Synthetic XML produces deserialisation errors, so the exact format had to be extracted from a legitimate response. Service logs confirmed injection — the fake “Critical Update” was accepted as inventoried.
4. SYSTEM Binary Execution
Triggering the full update flow causes the SYSTEM service to:
- Download from the attacker-controlled URL
- Verify package size — PASSED
- Verify SHA256 checksum — PASSED
- Verify Authenticode signature — PASSED
- Execute the binary as SYSTEM
The Authenticode check is the remaining barrier — payloads must be vendor-signed. But there is a BYOVD (Bring Your Own Vulnerable Driver) path: an older version of the vendor’s own kernel driver is WHQL-signed, not on the vulnerable-driver blocklist, loads even with HVCI enabled, and exposes arbitrary kernel read/write primitives. The driver has a known CVE but remains loadable on fully patched Windows 11; Andy explicitly declines to detail it further in the post.
The full chain was verified on Windows 11 25H2 (Build 26200). Ghidra decompilation, Frida dynamic analysis, and WCF interface reversing all ran through the MCP tools — stage the binary to hunt-kali, run Ghidra headless, then hook the live service with Frida to confirm behaviour. Submitted to the vendor and confirmed valid.
macOS App Distributor — Two Findings
The hunt rig is not Windows/Linux-only. Because the orchestrator runs on Mac, the macOS toolchain is also wired in — including Raptor. That combination netted two findings against a macOS application distribution platform via the vendor’s bounty programme.
Browser History Exfiltration — a bundled framework reads browser SQLite databases plus the macOS quarantine database on launch. Static analysis surfaced the lead; Frida dynamic analysis via the MCP RE tools confirmed actual query behaviour. The browser history query turned out to be scoped to a specific search term, but the quarantine query (SELECT * FROM LSQuarantineEvent) was completely unfiltered — exfiltrating every file the user had ever downloaded.
Debug RSA Key in Production Bundle — a debug.pem shipped in the production app turned out to be the jwt.io RS256 example key — meaning the private key is publicly known. Combined with CFPreferencesSetAppValue to override the Sparkle update framework’s signature verification key, the PoC was a Swift script plus Frida hook demonstrating cross-process preference injection enabling malicious update delivery.
These two are a good snapshot of the workflow: static RE identified the leads, Frida instrumentation confirmed behaviour, and the reporting MCP drafted the bounty submission. The Frida follow-up was what converted both from “needs more info” to triaged — a useful reminder that static-only findings often need runtime validation before vendors take them seriously.
Beyond the above there are also the following findings in progress:
- 3x LPEs on Windows affecting various vendors
- 4x RCE affecting various applications, mostly desktop apps
- 2x UAF in a library that is pending disclosure
- Handful of information disclosure across stacks of software on macOS / Windows
Lessons Learnt
The hallucination bin should be Gate 0. The first iteration of the system trusted its own output. That was a mistake. LLM-driven analysis produces confident-sounding assessments that may or may not match reality. The “guilty until proven innocent” approach — every finding starts in hallucinations/ — has a near-zero false positive rate. If Andy were starting over, this would be the first thing built.
Always verify from a low-privilege context. Multiple early findings turned out to be admin-only or SYSTEM-only triggers. The worst example was a hardware vendor’s diagnostic agent flagged as having an exploitable named pipe — from a SYSTEM context. From a standard user, the pipe was unreachable. Gate 3 (tool_lowpriv_check) should have been there from day one. Every finding needs to be verified as a standard user before it goes anywhere.
Record negative results. When a target turns out to be hardened (AM-PPL, SxS protection, strict signature validation), record that defence mechanism. The known-defence database now multiplicatively penalises hardened targets, preventing future campaigns from burning cycles on the same dead ends.
The knowledge loop compounds. Each campaign makes the next one more efficient. After 15+ campaigns, the system’s recommendations for what to fuzz and how to approach it are measurably better than cold-starting each time. The RAG queries before each campaign genuinely prevent the most expensive mistake in fuzzing: running the same campaign against the same binary with the same seeds and getting the same nothing.
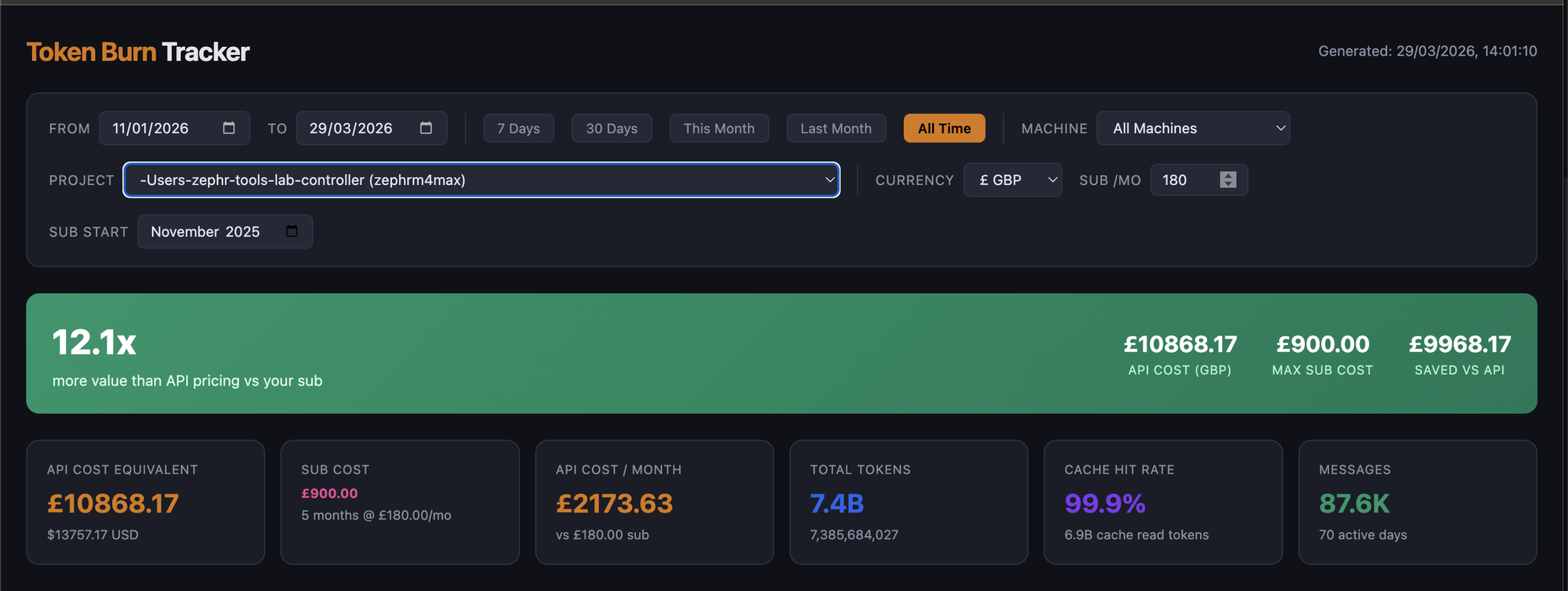
Cost Calculations
Five VMs on a Proxmox host, a Claude Max subscription, plus the time to build and maintain 300+ tools across eight MCP servers — that is not free. Andy was curious what the total cost would have been at API rates instead of the Max sub, so he built a tool to answer it.
Tracking Token Usage
The first problem is knowing what you are spending. Claude Code on Max is not billed per-token, but tokens are not free either — rate limits apply, and understanding consumption patterns tells you whether the subscription is paying for itself or whether you would be better off on API billing.
TokenBurn answers this. It is a self-hosted dashboard that pulls token-usage data from every machine running Claude Code, aggregates it, and breaks down consumption by model and project. Each machine runs a small sync script that parses local session data and exports JSON. The dashboard then shows daily trends, per-project breakdowns, hourly activity patterns, and — critically — a comparison of what the same usage would cost at API rates versus the flat subscription.
For security research specifically, usage is spiky. A hunt session might burn through significant context orchestrating a 15-step attack-surface enumeration, decompiling functions, cross-referencing findings, and drafting a disclosure — all in a single conversation — then nothing for a day while fuzzing runs. TokenBurn makes that pattern visible instead of leaving you guessing whether the subscription pays for itself.
Cost Per Finding
The goal was not to make money. Andy started hunting CVEs after netting two previously in his career (NVIDIA CVE-2020 and CVE-2017-3528); that number is now 4 from this process, with another few in progress with vendors.

You could argue this works out to roughly £5,000 per CVE on API costs alone — with a subscription it saved a great deal, and downstream bug payouts offset the subscription cost outright.
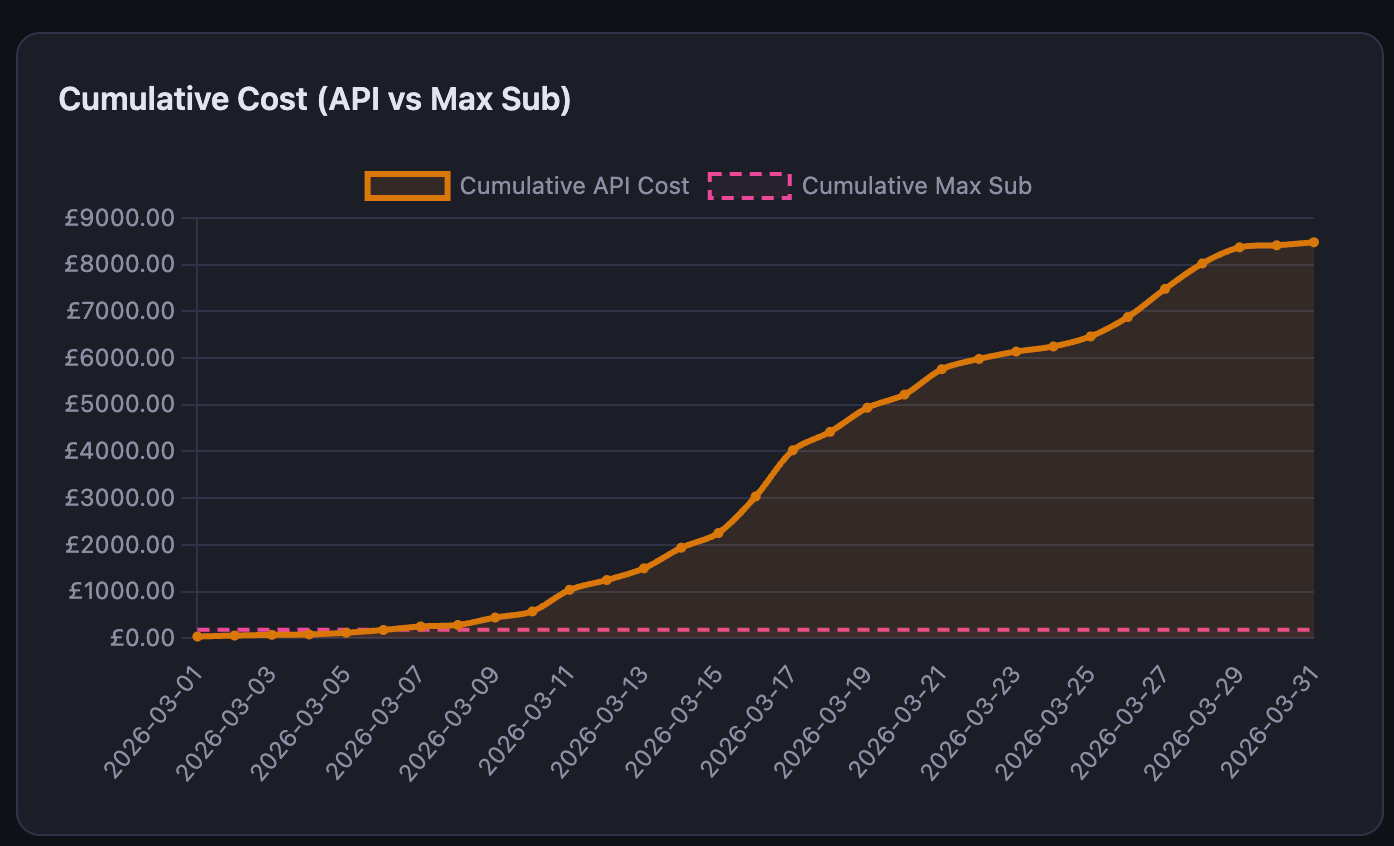
The system tracks cost natively. Each campaign records its creation timestamp, last update, and number of VMs allocated. The analytics module computes a straightforward metric: total compute hours (campaign duration multiplied by VM count) divided by validated findings — not findings in the hallucination bin, only findings that survived all the gates.
Most campaigns produce zero validated findings. Fuzzing runs that consume hundreds of VM-hours come back with nothing exploitable. The campaigns that do produce findings often took less wall-clock time than the ones that didn’t, because the knowledge loop steered them toward targets with higher prior probability of being vulnerable rather than grinding on hardened binaries.
The trend matters more than any single number. Cost-per-finding has decreased meaningfully across the lifetime of the system. The early campaigns were expensive in every sense — building tooling, learning what doesn’t work, populating the hallucination bin with confident-sounding nonsense. Recent campaigns benefit from all of that accumulated context: the RAG index knows which binaries are hardened, the bounty intelligence knows which programmes are worth the time, and the grammar generators know which file-format fields are interesting.
ROI-Driven Target Selection
Before any campaign starts, the bounty-intelligence module estimates expected return. The maths is deliberately pragmatic, not sophisticated:
Expected ROI = conservative payout estimate / estimated hunt hours
The inputs are straightforward. Hunt-hour estimates come from experience: a DLL hijack typically takes around 8 hours to identify and prove, an LPE around 20, an RCE around 40, and memory-corruption classes like type confusion or use-after-free can run to 80 easily. These are conservative — they assume you don’t get lucky and that validation (the hallucination-bin flow) costs real time.
Payout estimates use the minimum from each programme’s published range, not typical or maximum. This is deliberate: the system should be pessimistic about payouts and optimistic about nothing. The 100 tracked bounty programmes carry payout ranges per vulnerability class, from info-disclosure at the low end to hypervisor escape at the top.
Competition adjustment is the final multiplier. A low-competition programme keeps 90% of expected value. A high-competition programme like a major OS vendor drops to 40% — you might find the bug, but so might three other researchers who will report it first. Very-high competition drops to 20%. This stops the system fixating on the biggest headline bounties where the odds of being first-to-report are slim.
The net effect: the system naturally gravitates toward the sweet spot of under-scrutinised software with decent bounties — third-party system utilities, OEM management agents, enterprise middleware. Software that ships on millions of machines without attracting the same researcher attention as Chrome or the Windows kernel. The OEM update-service 0-day above is a direct product of that ranking.
An Honest Review
The system has paid for itself. Bounty payouts from validated findings have exceeded the combined cost of the Proxmox hardware, the subscription, and the time invested in building the tooling. Does that mean you can replicate everything and make a quick buck? Maybe — but that is the rose-tinted summary.
The full picture includes a lot of campaigns that found nothing. Coverage plateaus that led nowhere. Crashes that looked exploitable until they didn’t. The hallucination bin is larger than the findings directory by a significant margin — and that is working as intended. It means the system is catching its own false positives before they waste anyone’s time. There is also a lot of human input: Andy feeds in his accumulated experience to tune the tooling, and occasionally has to push back when the LLM forgets its system prompt and starts querying the ethics of security research.
What makes the economics work long-term is not any single finding — it is the compounding effect across all of them. Each failed campaign still contributes to the knowledge base; each negative result (this binary is AM-PPL, this named pipe is admin-only) prevents future campaigns from repeating the same dead end. The system that runs its twentieth campaign is materially cheaper to operate per-finding than the one that ran its first, even though the subscription cost is identical. Andy has also been steadily tweaking per-campaign CLAUDE.md files and offloading more work to local models to drive token cost down.
How the Pieces Slot Together
For anyone thinking about building something similar, the high-level architecture is:
Thin server wrappers, thick business logic. MCP server files are just @mcp.tool() decorators around function calls. All the real work lives in dedicated modules — some written by Claude, some written by hand. That lets you test and iterate on the business logic independently of the MCP plumbing.
Shared sessions. Connect once per server, sessions persist across all tool calls in a conversation. When you are chaining 10+ steps (stage binary, decompile, identify function, set breakpoint, trace execution, analyse crash), reconnecting at each step would burn through tokens and sanity in equal measure.
Uniform fuzzing interface. Every domain has the same tool pattern — setup/start/status/crashes/stop. The autonomous engine doesn’t need domain-specific dispatch logic; it just picks the right domain and calls the same sequence.
Everything feeds the loop. Crashes, findings, coverage data, MSRC advisories, patch diffs, bounty outcomes — all indexed, all searchable, all informing the next hunt. The system that ran its first campaign knew nothing; the one running its twentieth has opinions about which binaries to target and which to skip, plus the accumulated context from prior brain dumps and prior research.
What Comes Next?
The system currently needs Andy to make judgment calls at key points — primarily deciding whether a crash is worth pursuing, whether a finding chain is realistic, and whether a target’s defences make it impractical. The next step is tightening that feedback loop so more of those decisions can be informed by the accumulated knowledge base rather than gut instinct. Not fully autonomous (we’re not there yet, and the hallucination bin exists for a reason), but better at surfacing the right information at the right time.
Andy is also working on his own gated delta network + MoE transformer-based model, originally based on Qwen, expanded with additional data and re-weighted to focus on his own research and methodology.
If you want to dig into MCP for security research, the protocol is well-documented at modelcontextprotocol.io. The hard part isn’t building the servers — that’s straightforward Python. The hard part is designing the validation pipeline so you can trust the output. Start with the hallucination bin.
Key Takeaways
- Hallucination bin = Gate 0. Every finding is guilty until proven innocent across four validation gates. Without it, an LLM-driven pipeline floods you (and vendors) with confident nonsense.
- Always verify as a standard user. Gate 3 (low-privilege reachability check) catches the most painful early class of false positives — “exploit” paths that only work from SYSTEM or admin.
- Negative results are first-class data. Recording defence mechanisms (AM-PPL, SxS protection, strict Authenticode) stops the next campaign re-hitting the same wall.
- Grammar-based fuzzing > random bytes for parsers. Both Go CVEs (TIFF IFD offset, GPOS class-count product) needed structurally valid input with adversarial fields, not random junk.
- The knowledge loop compounds. Cost-per-finding drops over the system’s lifetime even though the per-day subscription cost is flat — failed campaigns still enrich the next campaign’s priors.
- ROI-driven target selection beats headline bounties. Pessimistic payout estimates plus a competition multiplier push the system toward under-scrutinised OEM/middleware code, which is where the OEM SYSTEM chain came from.
- Static analysis identifies leads; dynamic instrumentation closes them. Both macOS findings stalled at “needs more info” until Frida confirmed runtime behaviour.
Defensive Recommendations
- Audit any local SYSTEM service exposing named pipes or WCF endpoints. Authentication must run on the server side, not in the client. Per-method privilege checks must be uniform — one method without an admin check is enough for the whole chain to fall.
- Never trust attacker-controlled URLs in SYSTEM-context fetches. If a method on a privileged service accepts a URL parameter, treat it as SSRF until proven otherwise — allowlist host/scheme, reject internal ranges, and log all outbound requests with caller context.
- Authenticode is not enough on its own. A signed-but-stale vulnerable driver (BYOVD) breaks every Authenticode-only trust model. Block on Microsoft’s vulnerable-driver blocklist, enable HVCI, and inventory driver versions on hosts at scale.
- Cap allocations in untrusted-input parsers. The TIFF and SFNT bugs are both single-line “trust the size field” mistakes. Enforce
maxTableLength-style caps before allocating; reject early if claimed sizes exceed the input. - Audit every parser for integer overflow in size calculations. The varLenView overflow in
x/image/font/sfntis generic to anything multiplyinguint16dimensions before allocating. - Scan production bundles for embedded private keys. A
debug.pemthat turns out to be the jwt.io example key is not a hypothetical — bake a pre-release scan over your release artifacts for known-public PEMs. - Lock down SQLite reads in shipped frameworks. Unbounded queries like
SELECT *against the macOS quarantine database leak the user’s entire download history; scope every query. - Run binary-diffing on every Patch Tuesday delivery. If a third-party MCP can do it autonomously, so can your attacker’s automation — assume patch-derived n-days will be weaponised quickly.
Conclusion
The autonomous-hunt-with-MCP design is interesting less because of any one trick and more because of the discipline baked into it — a hallucination bin that treats every LLM output as suspect, a four-gate validation pipeline that filters anything not reproducible as a standard user, a RAG loop that turns every failed campaign into priors for the next one, and a bounty-intelligence module that nudges the orchestrator toward under-scrutinised software. The economics are modest individually but compound across campaigns. For defenders, the pattern of findings — SYSTEM services with client-side auth, unchecked size fields in standard-library parsers, embedded debug PEMs, signed-but-stale drivers — is also a reasonable checklist for what an LLM-augmented attacker is likely to surface next.
Original text: “Autonomous Vulnerability Hunting with MCP” by Andy Gill at ZephrSec – Adventures In Information Security.